prometheus告警配置
prometheus告警配置
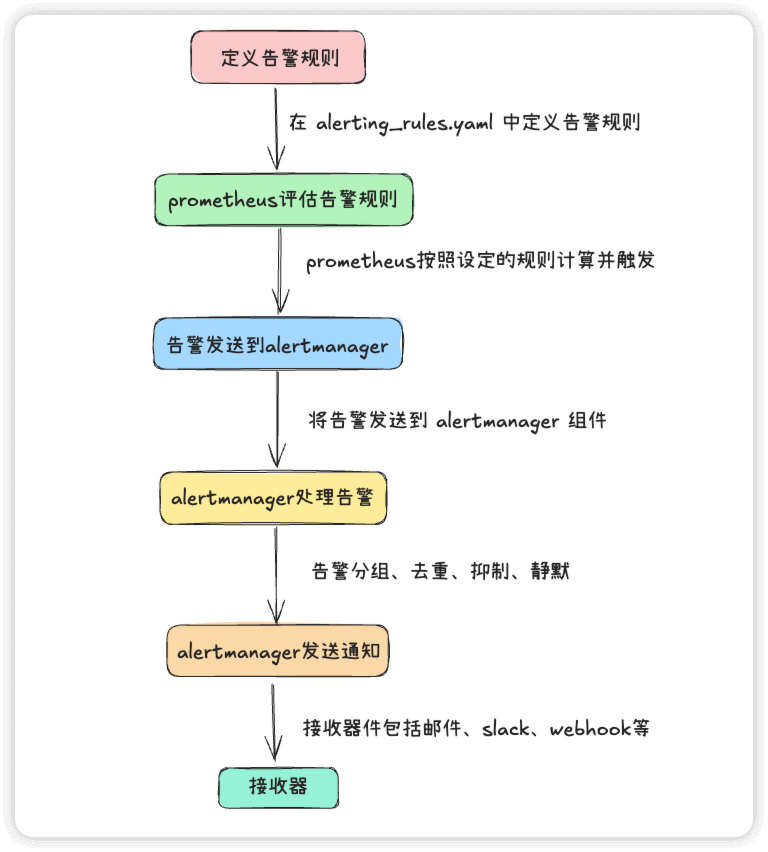
prometheus告警流程示意图
相关文件
prometheus.yml 文件中有如下配置
rule_files:
- /etc/config/recording_rules.yml
- /etc/config/alerting_rules.yml
- /etc/config/rules
- /etc/config/alerts
| 文件 | 说明 |
|---|---|
/etc/config/recording_rules.yml | 定义预先计算常用的或计算密集型的 PromQL 表达式,并将结果存储为新的时间序列,目的是提高查询性能并简化复杂查询的使用 |
/etc/config/alerting_rules.yml | 告警规则文件,定义触发告警的条件 |
/etc/config/rules | 将被删除,可查看 官方文档说明 |
/etc/config/alerts | 将被删除,可查看 官方文档说明 |
配置prometheus告警规则
在 alerting_rules.yml 文件中新增告警规则
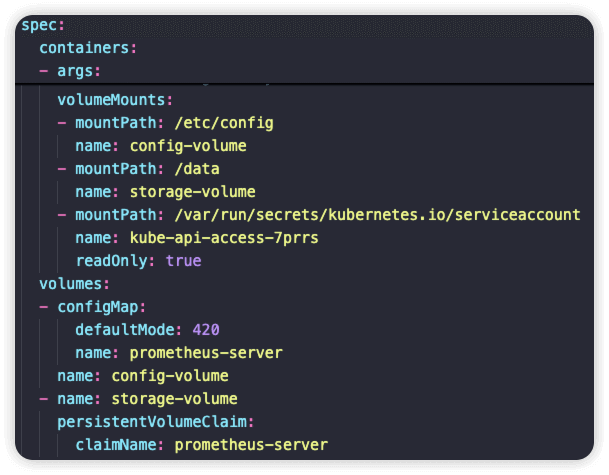
在prometheus pod的yaml文件中,/etc/config 目录是以名为 prometheus-server 的configmap挂载的
spec
......
volumeMounts:
- mountPath: /etc/config
name: config-volume
readOnly: true
......
volumes:
- configMap:
defaultMode: 420 # 表示文件权限为 rw-r-----
name: prometheus-server
name: config-volume
因此需要编辑 cm prometheus-server 的 data 字段下的 alerting_rules.yml
groups:
- name: node-memory-alerts
rules:
- alert: 内存使用率过高
expr: avg by (node, instance) (100 * (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes))) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "节点 {{ $labels.node }} 内存使用率过高"
description: "节点 {{ $labels.node }}(实例 {{ $labels.instance }})的内存使用率当前为 {{ printf \"%.2f\" $value }}%,已�超过 80%,持续时间超过 2 分钟。"
编辑完成后查看
$ kubectl get cm prometheus-server -o yaml
apiVersion: v1
data:
alerting_rules.yml: |
groups:
- name: node-memory-alerts
rules:
- alert: 内存使用率过高
expr: avg by (node, instance) (100 * (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes))) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "节点 {{ $labels.node }} 内存使用率过高"
description: "节点 {{ $labels.node }} (实例 {{ $labels.instance }}) 内存使用率超过 80%,当前值为 {{ printf \"%.2f\" $value }}%,持续时间超过 2 分钟。"
......
字段说明
| 字段 | 说明 |
|---|---|
groups | 告警规则组的列表 |
name | 规则组的名称,此处为 node-memory-alerts |
rules | 具体的告警规则列表 |
alert | 告警名称,此处为 内存使用率过高 |
expr | PromQL 表达式,计算内存使用率是否超过 80% |
for | 持续时间,若超过 2 分钟仍满足条件,则触发告警 |
labels | 告警标签 |
severity | 告警级别,没有固定标准,一般为 info(信息)、 warning(警告)、critical(严重)、emergency(紧急) |
annotations | 告警的额外说明信息 |
summary | 告警摘要,显示受影响的节点 |
description | 告警详细描述,包含节点、实例及当前内存使用率 |
配置完告警后,此时prometheus ui中显示的状态是 PENDING ,意思为告警条件刚触发,尚未进入告警状态(这里为了测试,把PromQL中的阈值改为了大于20)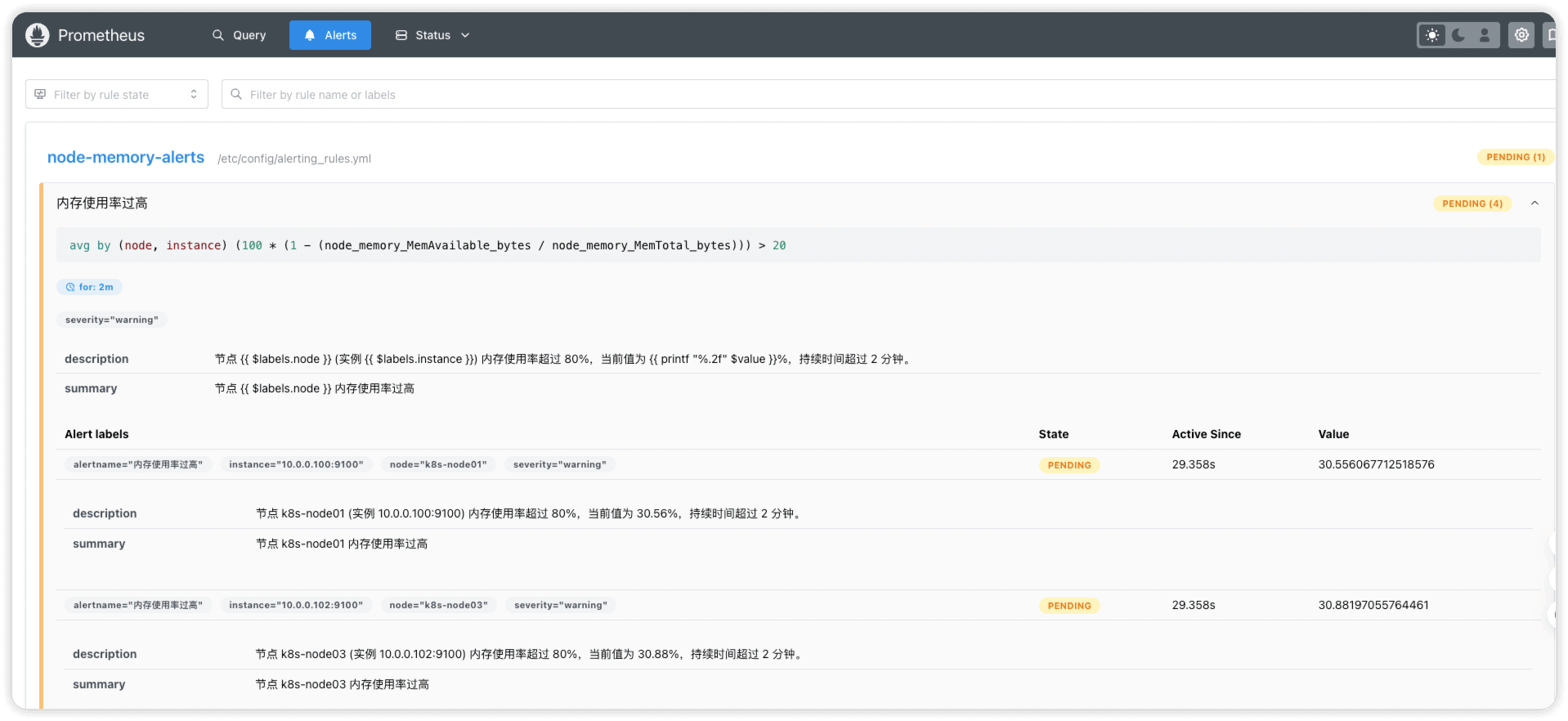
如果持续时间超过 for 字段定义的时间(这里为2分钟),则状态会变为 FIRING ,意思为告警条件持续满足,prometheus已经开始触发告警
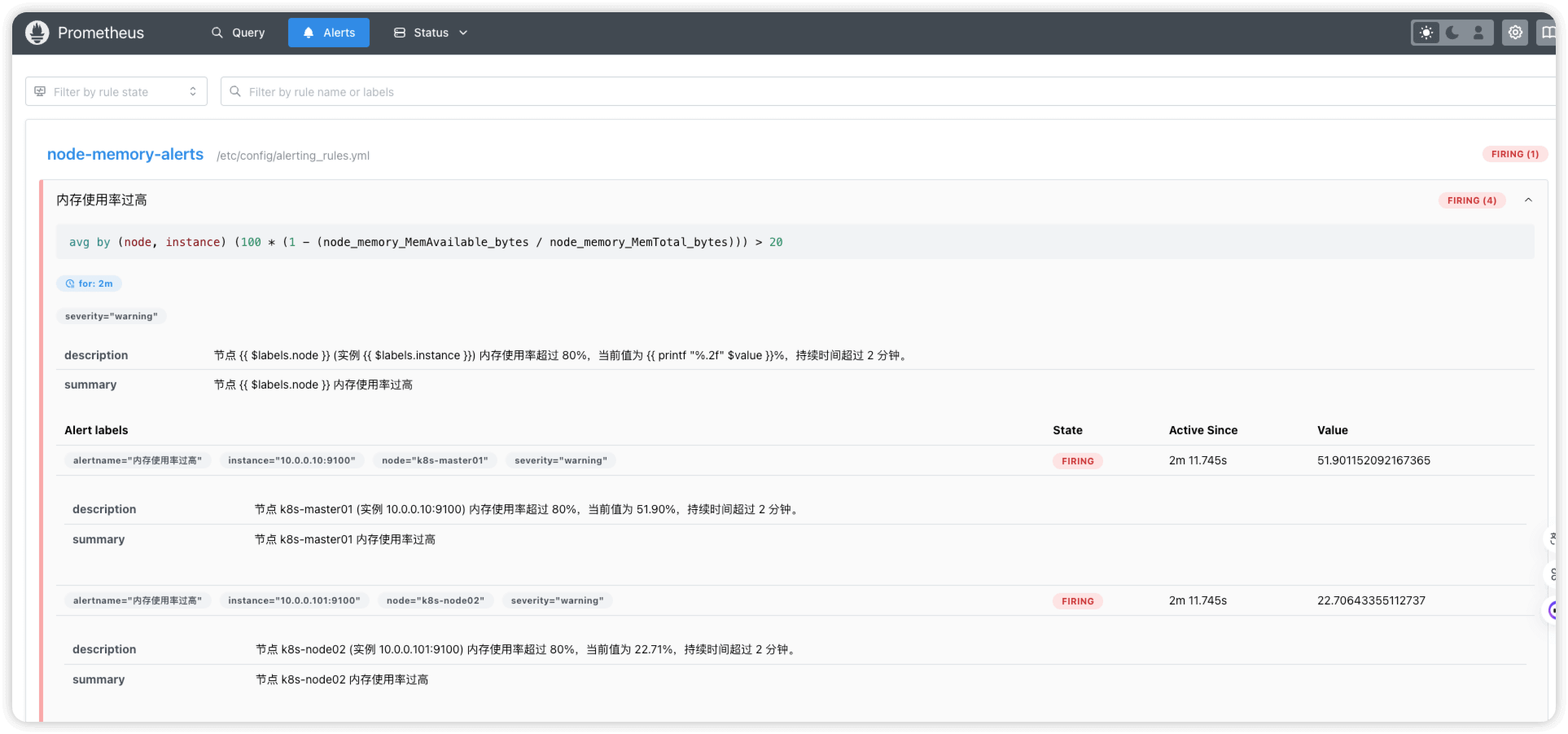
当告警恢复时,状态就会变为 INACTIVE
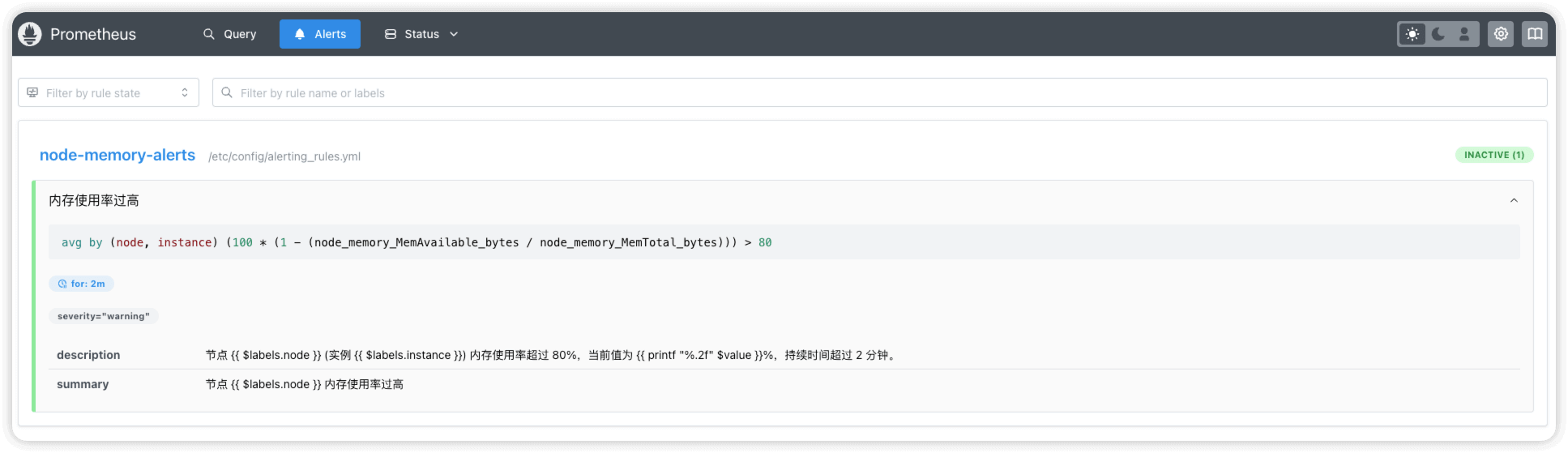
prometheus告警状态码
| 状态码 | 说明 |
|---|---|
PENDING | 告警条件刚触发,尚未进入告警状态,通常会有一段时间的延迟 |
FIRING | 告警条件持续满足,Prometheus 已经开始触发告 |
INACTIVE | 告警条件不再满足,告警已恢复 |
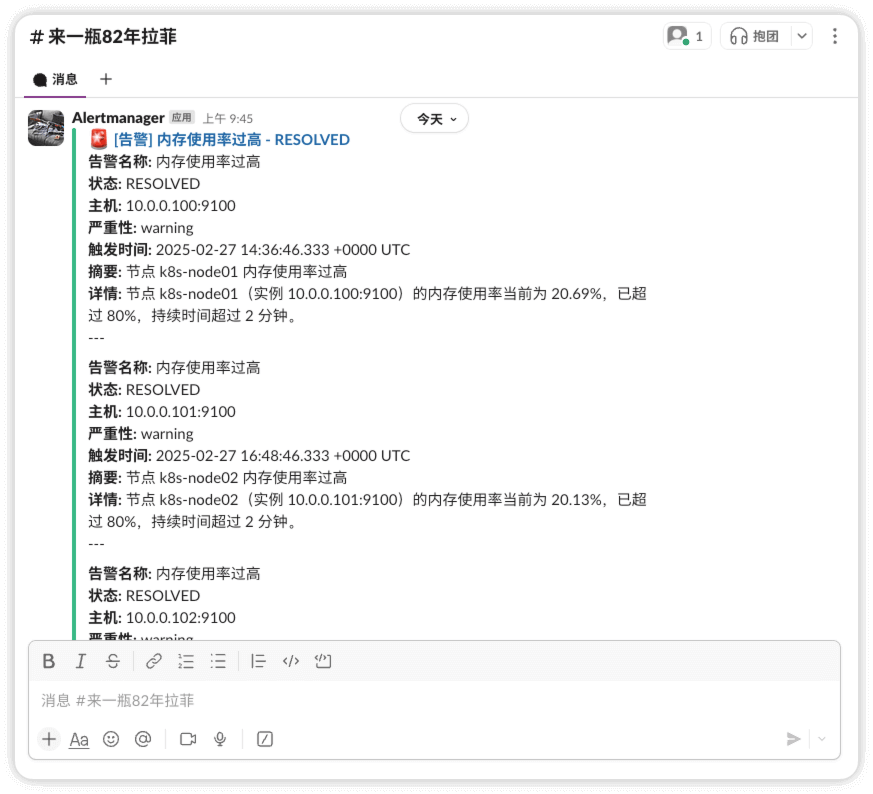
在alertmanager ui界面中可以查看到告警信息
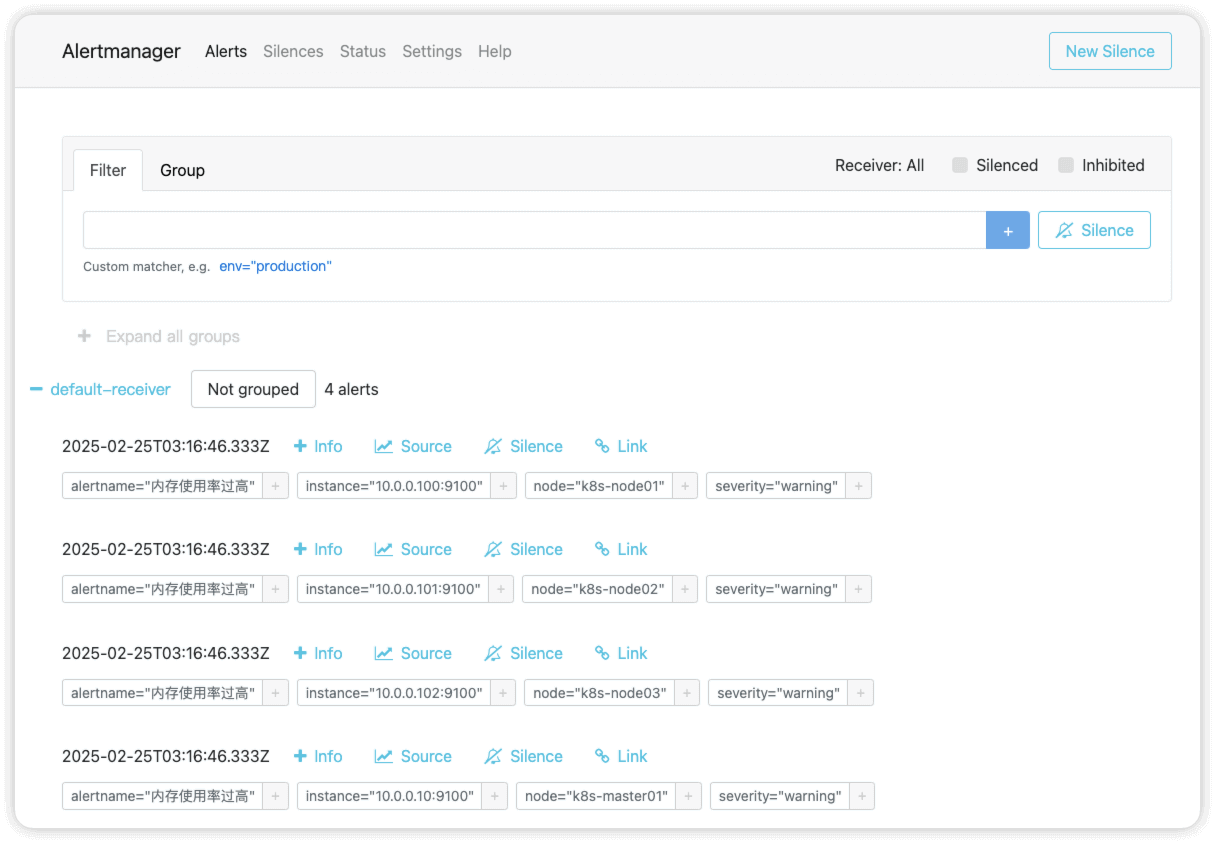
配置alertmanager发送告警
alertmanager.yml 文件默认内容如下
global: {} # 全局配置(比如 SMTP、Slack Webhook 地址等),这里为空,表示未定义全局设置
receivers: # 告警接收者列表,当前只有 default-receiver,但没有具体的通知方式
- name: default-receiver
# 告警路由规则,决定告警如何分组和发送到哪个 receiver
route:
group_interval: 5m # 组内的新告警(同一规则匹配的)每 5 分钟发送一次
group_wait: 10s # 在同一组告警首次触发后,等待 10 秒再发送,防止告警风暴
receiver: default-receiver # 默认将所有告警发送给 default-receiver
repeat_interval: 3h # 如果告警未恢复,每 3 小时重复发送一次
templates:
- /etc/alertmanager/*.tmpl # 指定模板文件路径(可用于自定义告警格式),当前为 /etc/alertmanager/*.tmpl,但默认没有模板文件
配置slack告警
slack相关配置
注册账号
在 slack官网 注册账号
创建工作区

定义工作区名称
一共有多个步骤,按照提示填写即可,最后一步选择开始使用
创建完成
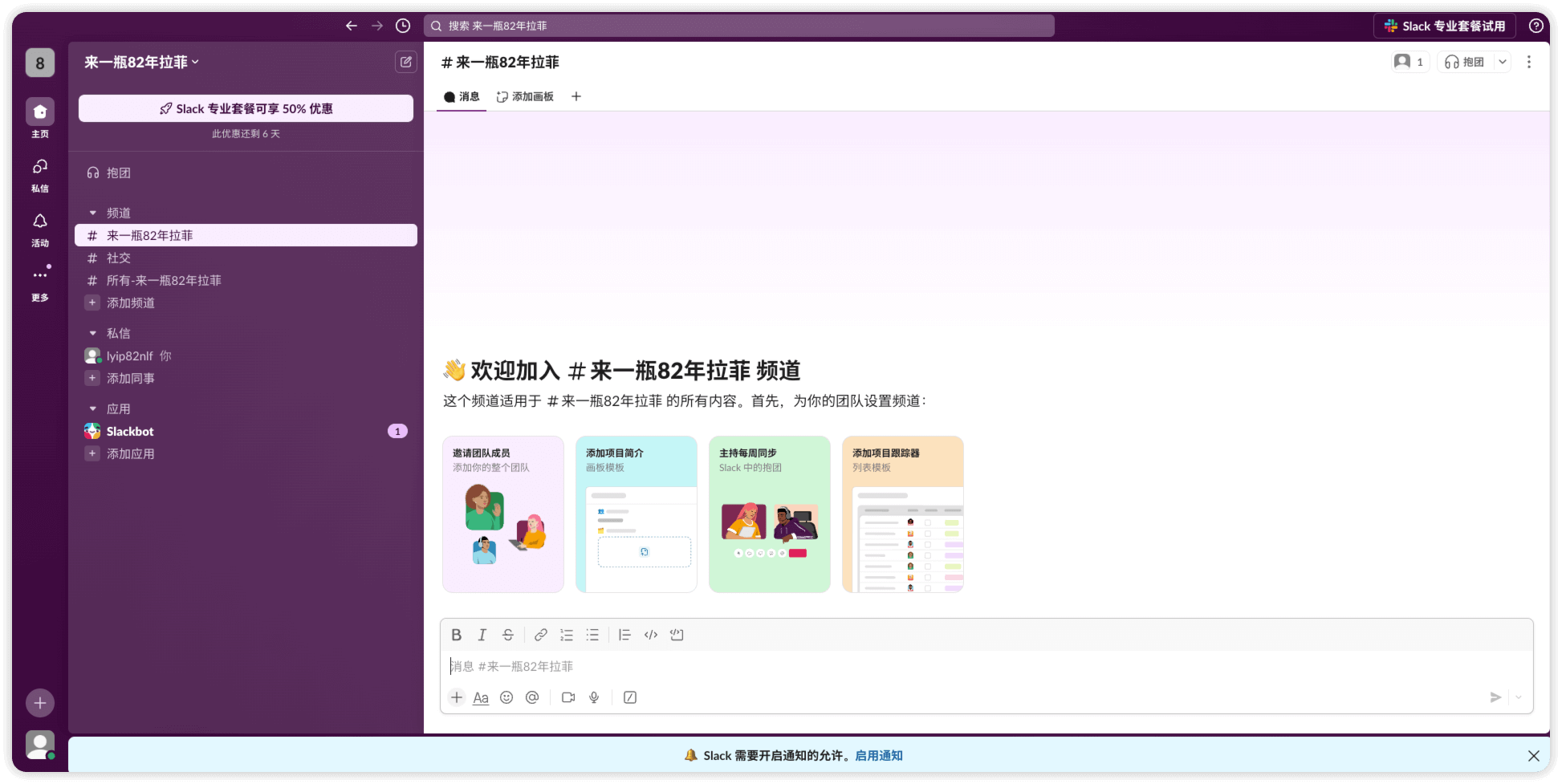
创建 incomming webhooks 应用
第一次创建的工作区的名称也是频道的名称
点击 添加应用
搜索 incomming webhooks
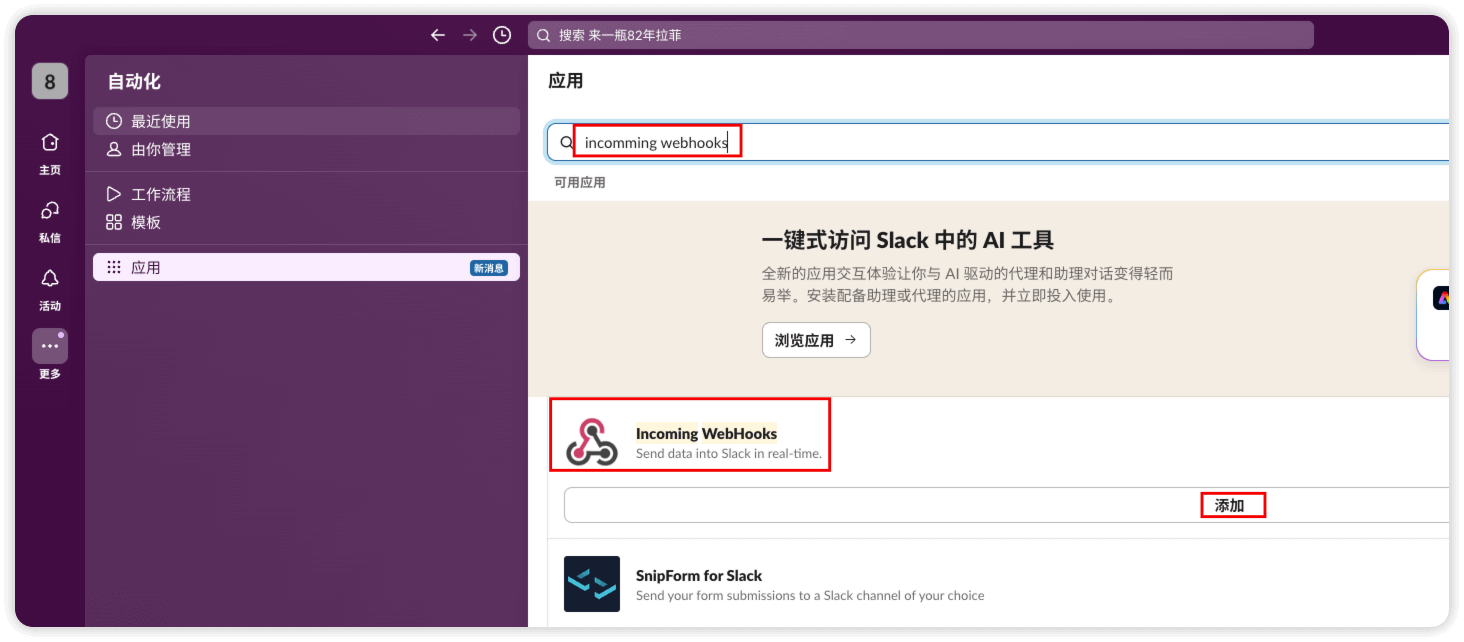
添加到slack
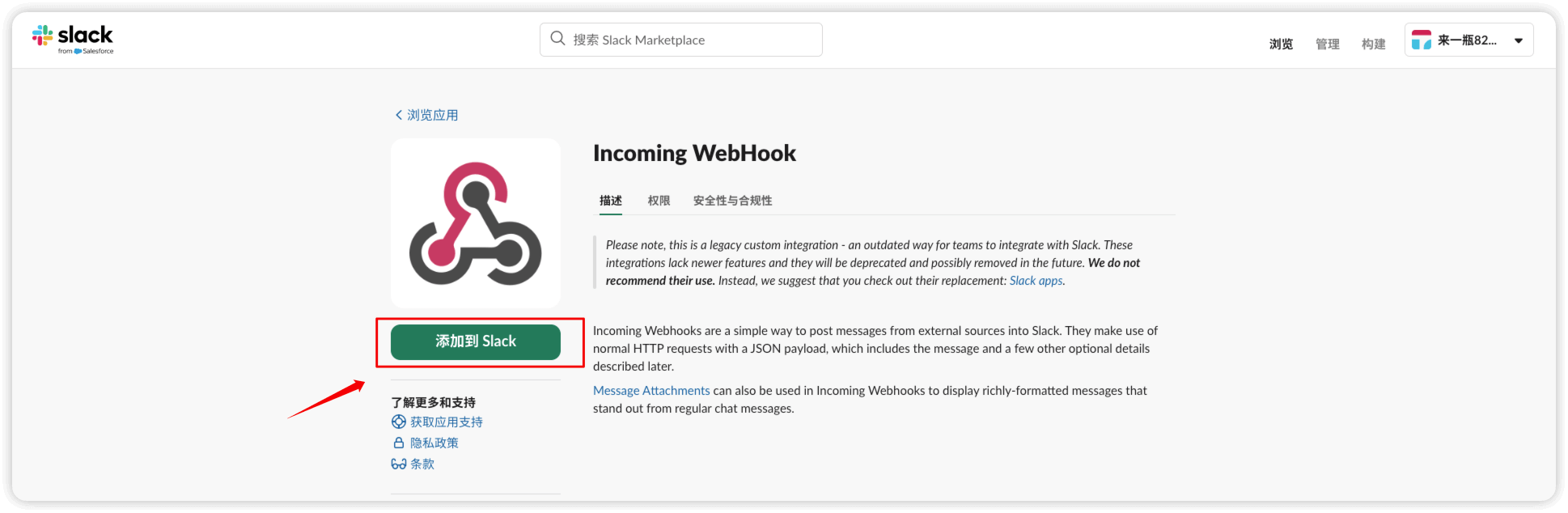
选择一个频道并点击 add incoming webhook integration
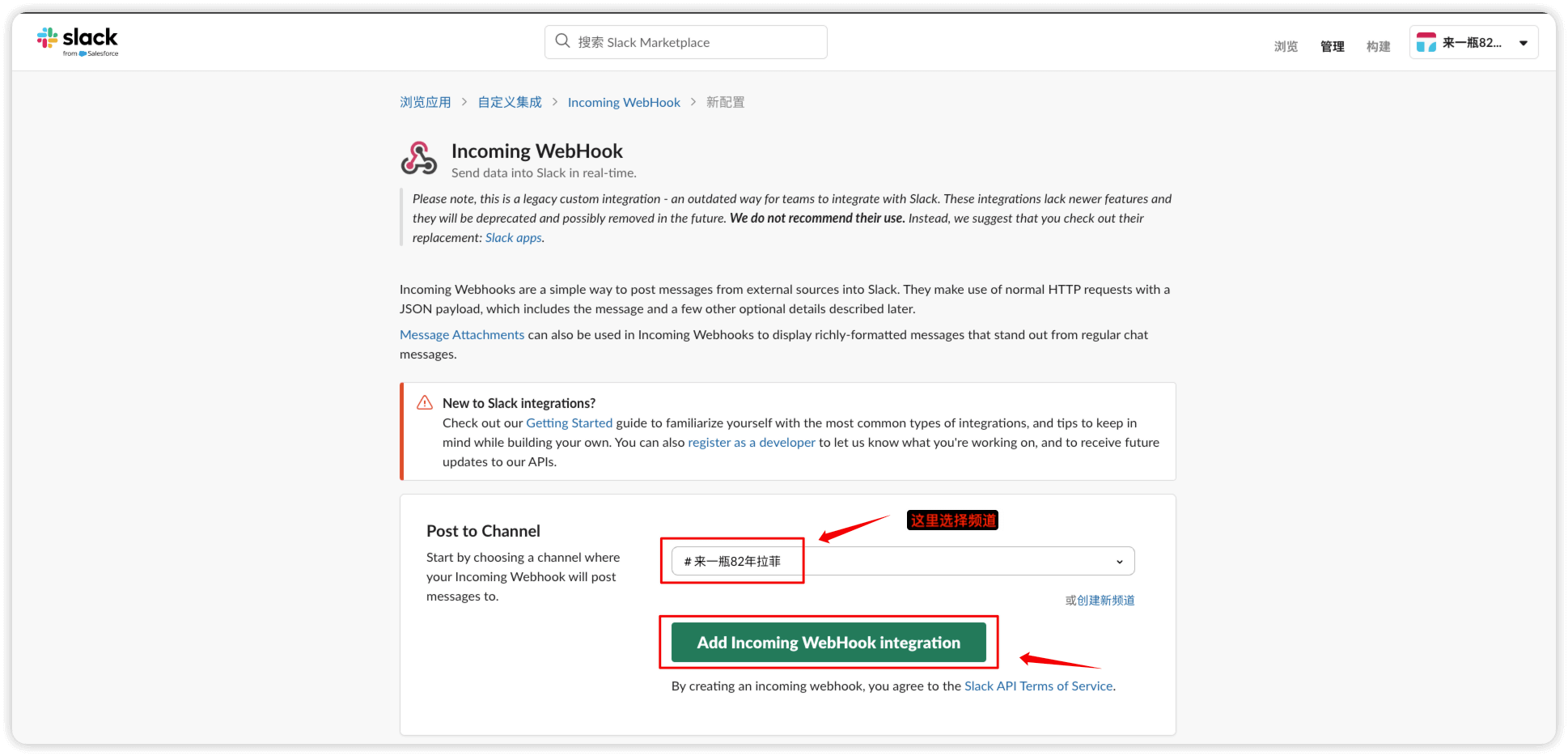
添加完成,这里需要用到的就是 webhook url
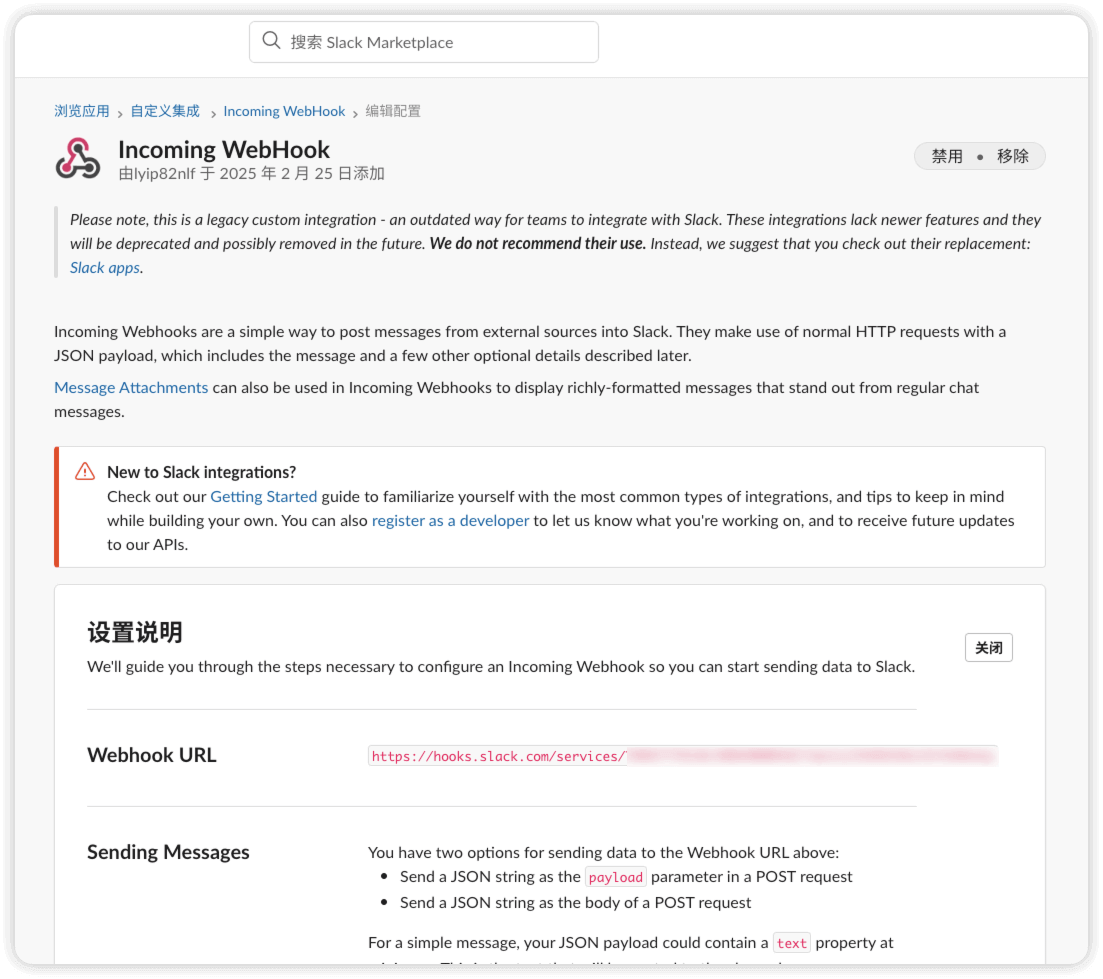
自定义名称
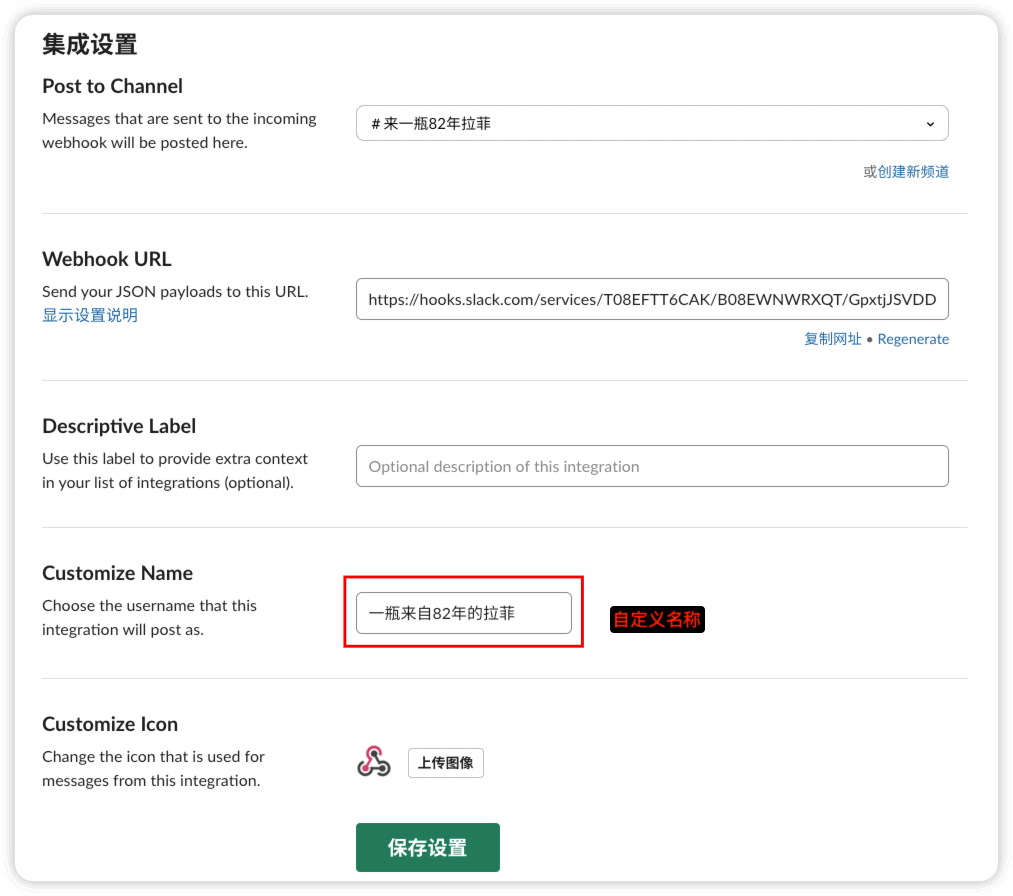
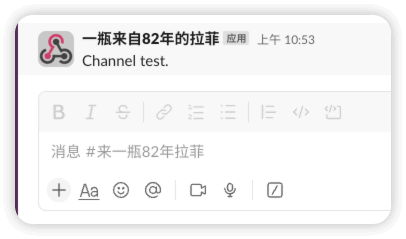
可通过如下命令进行测试
curl -d "payload={'text': 'Channel test.'}" https://hooks.slack.com/services/xxx
alertmanager配置
新增默认告警接收器
slack
cm prometheus-alertmanager 的默认内容
$ kubectl get cm prometheus-alertmanager -o yaml
apiVersion: v1
data:
alertmanager.yml: |
global: {}
receivers:
- name: default-receiver
route:
group_interval: 5m
group_wait: 10s
receiver: default-receiver
repeat_interval: 3h
templates:
- /etc/alertmanager/*.tmpl
kind: ConfigMap
......
修改为如下
这里我们使用了slack作为告警接收器,需要填写slack incomming webhooks 的url
global:
# 全局配置,这里设置了解决告警的超时时间
resolve_timeout: 5m # 设置告警解决的超时时间,超时后自动解决告警
receivers:
- name: 'slack' # 接收告警的目标,定义为 'slack',用于发送到 Slack
slack_configs:
- api_url: 'xxx' # Slack Webhook URL,用来发送告警到 Slack
channel: 'alert-robot' # Slack 频道名称,告警将发送到此频道
send_resolved: true # 是否在告警解决时发送通知,true 表示发送解决通知
title: '{{ template "slack.default" . }}' # 使用 "slack.default" 模板来格式化标题
text: '{{ template "slack.default" . }}' # 使用 "slack.default" 模板来格式化通知文本内容
route:
# 告警的路由配置
group_by: ['alertname', 'cluster', 'service'] # 将相同 alertname、cluster 和 service 的告警分组
group_wait: 30s # 每组告警等待的时间,告警发送前的等待时间,通常是为了等待其他告警
group_interval: 5m # 在同一组告警中的告警发送间隔,避免频繁发送相同类型的告警
repeat_interval: 12h # 如果告��警持续存在,重新发送告警的时间间隔
receiver: 'slack' # 告警发送的接收目标,这里是 Slack 配置
templates:
- '/etc/alertmanager/*.tmpl' # 模板文件路径,Alertmanager 会使用这个模板来格式化 Slack 通知的内容
修改完成后查看cm
$ kubectl get cm prometheus-alertmanager -o yaml
apiVersion: v1
data:
alertmanager.yml: |-
global:
# 全局配置,这里设置了解决告警的超时时间
resolve_timeout: 5m # 设置告警解决的超时时间,超时后自动解决告警
receivers:
- name: 'slack' # 接收告警的目标,定义为 'slack',用于发送到 Slack
slack_configs:
- api_url: 'xxx' # Slack Webhook URL,用来发送告警到 Slack
channel: 'xxx' # Slack 频道名称,告警将发送到此频道
send_resolved: true # 是否在告警解决时发送通知,true 表示发送解决通知
title: '{{ template "slack.default" . }}' # 使用 "slack.title" 模板来格式化标题
text: '{{ template "slack.default" . }}' # 使用 "slack.text" 模板来格式化通知文本内容
route:
# 告警的路由配置
group_by: ['alertname', 'cluster', 'service'] # 将相同 alertname、cluster 和 service 的告警分组
group_wait: 30s # 每组告警等待的时间,告警发送前的等待时间,通常是为了等待其他告警
group_interval: 5m # 在同一组告警中的告警发送间隔,避免频繁发送相同类型的告警
repeat_interval: 12h # 如果告警持续存在,重新发送告警的时间间隔
receiver: 'slack' # 告警发送的接收目标,这里是 Slack 配置
templates:
- '/etc/alertmanager/*.tmpl' # 模板文件路径,Alertmanager 会使用这个模板来格式化 Slack 通知的内容
kind: ConfigMap
......
新增告��警通知模版文件
slack
在alertmanager pod的yaml文件中,/etc/alertmanager 目录是以名为 prometheus-alertmanager 的configmap挂载的
spec:
......
volumeMounts:
- mountPath: /etc/alertmanager
name: config
......
volumes:
- configMap:
defaultMode: 420 # 表示文件权限为 rw-r-----
name: prometheus-alertmanager
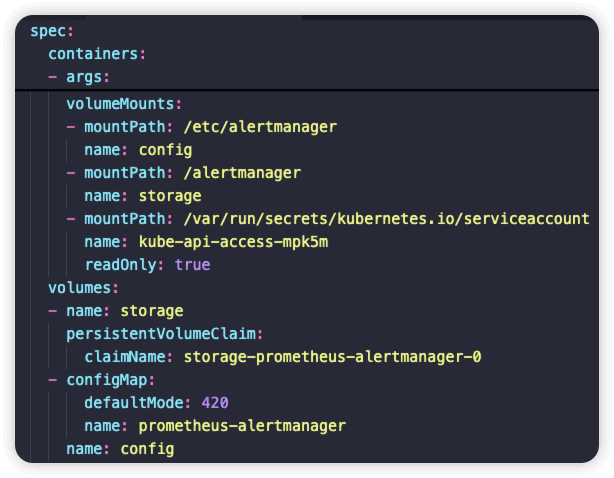
告警通知模版文件为 /etc/alertmanager/*.tmpl ,可以在 官方文档 中查看默认的告警通知模版,也可以自定义,因此需要编辑 cm prometheus-alertmanager 下的data字段,新增 *.tmpl
新增如下内容
{{ define "slack.title" }}
:rotating_light: [告警] {{ .CommonLabels.alertname }} - {{ .Status | toUpper }}
{{ end }}
{{ define "slack.text" }}
{{ range .Alerts }}
*告警名称:* {{ .Labels.alertname }}
*状态:* {{ .Status | toUpper }}
*主机:* {{ .Labels.instance }}
*严重性:* {{ .Labels.severity }}
*触发时间:* {{ .StartsAt }}
{{ if .Annotations.summary }}*摘要:* {{ .Annotations.summary }}{{ end }}
{{ if .Annotations.description }}*详情:* {{ .Annotations.description }}{{ end }}
---
{{ end }}
{{ end }}
修改完成后查看cm
$ kubectl get cm prometheus-alertmanager -o yaml
apiVersion: v1
data:
alertmanager.yml: |-
global:
# 全局配置,这里设置了解决告警的超时时间
resolve_timeout: 5m # 设置告警解决的超时时间,超时后自动解决告警
receivers:
- name: 'slack' # 接收告警的目标,定义为 'slack',用于发送到 Slack
slack_configs:
- api_url: 'xxx' # Slack Webhook URL,用来发送告警到 Slack
channel: '来一瓶82年拉菲' # Slack 频道名称,告警将发送到此频道
send_resolved: true # 是否在告警解决时发送通知,true 表示发送解决通知
title: '{{ template "slack.title" . }}' # 使用 "slack.title" 模板来格式化标题
text: '{{ template "slack.text" . }}' # 使用 "slack.text" 模板来格式化通知文本内容
route:
# 告警的路由配置
group_by: ['alertname', 'cluster', 'service'] # 将相同 alertname、cluster 和 service 的告警分组
group_wait: 30s # 每组告警等待的时间,告警发送前的等待时间,通常是为了等待其他告警
group_interval: 5m # 同一组告警中的告警发送间隔,避免频繁发送相同类型的告警
repeat_interval: 12h # 如果告警持续存在,重新发送告警的时间间隔
receiver: 'slack' # 告警发送的接收目标,这里是 Slack 配置
templates:
- '/etc/alertmanager/*.tmpl' # 模板文件路径,Alertmanager 会使用这个模板来格式化 Slack 通知的内容
slack_notification.tmpl: |
{{ define "slack.title" }}
:rotating_light: [告警] {{ .CommonLabels.alertname }} - {{ .Status | toUpper }}
{{ end }}
{{ define "slack.text" }}
{{ range .Alerts }}
*告警名称:* {{ .Labels.alertname }}
*状态:* {{ .Status | toUpper }}
*主机:* {{ .Labels.instance }}
*严重性:* {{ .Labels.severity }}
*触发时间:* {{ .StartsAt }}
{{ if .Annotations.summary }}*摘要:* {{ .Annotations.summary }}{{ end }}
{{ if .Annotations.description }}*详情:* {{ .Annotations.description }}{{ end }}
---
{{ end }}
{{ end }}
kind: ConfigMap
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: monitor
creationTimestamp: "2025-02-27T08:31:15Z"
labels:
app.kubernetes.io/instance: prometheus
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: alertmanager
app.kubernetes.io/version: v0.27.0
helm.sh/chart: alertmanager-1.13.1
name: prometheus-alertmanager
namespace: monitor
resourceVersion: "108267"
uid: 2f9f897a-c092-4c42-9e82-7850a93f4ce7
查看告警
slack
告警发生
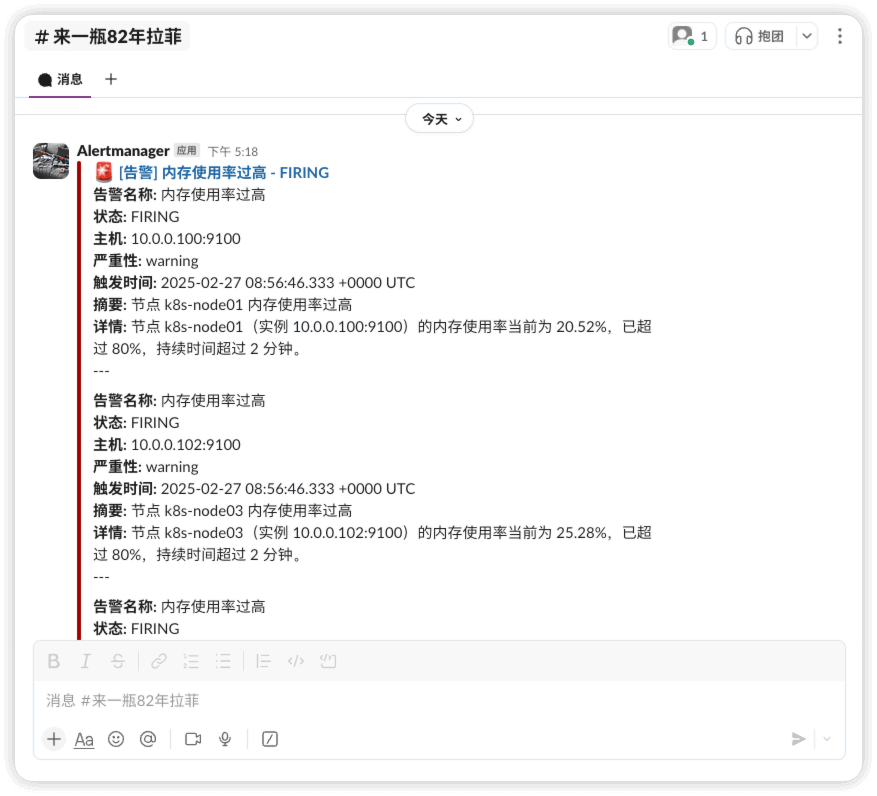
告警恢复