django ORM
[toc]
5.ORM
5.1 ORM简介
- MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动
- ORM是“对象-关系-映射”的简称。(Object Relational Mapping,简称ORM)
- ORM执行的过程
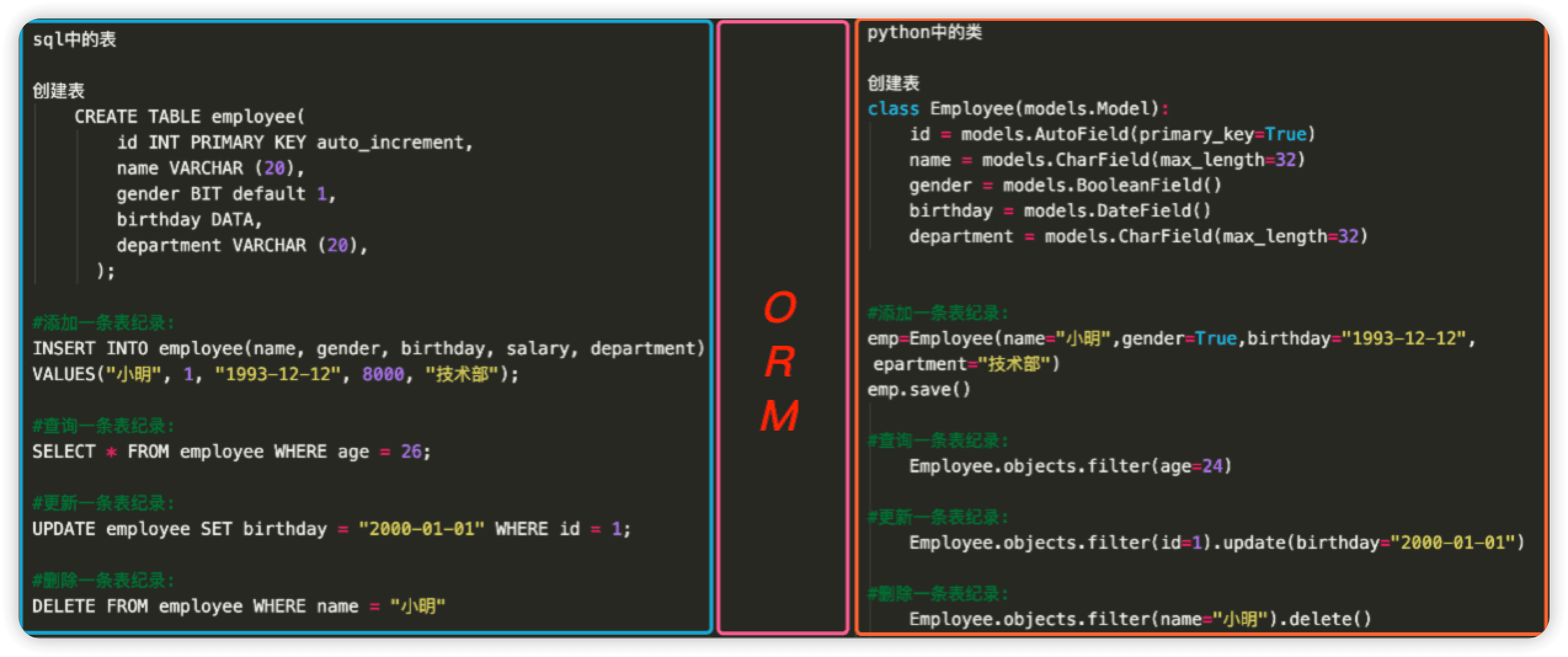
- 类对象--->sql--->pymysql--->mysql服务端--->磁盘,orm其实就是将类对象的语法翻译成sql语句的一个引擎
ORM与原生SQL对比
5.2 ORM操作
5.2.1 ORM连接mysql
这里先来一个orm连接mysql并创建一张表的示例
第一步、修改settings配置文件,配置mysql相关信息
#先注释默认项
# DATABASES = {
# 'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
# }
# }
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '数据库名',
'HOST': '数据库IP',
'PORT': '数据库端口',
'USER': '用户',
'PASSWORD': '密码'
}
}
第二步、在项目目录下的同名目录下的__init__.py文件中写上以下内容,来指定pymysql作为连接客户端
import pymysql
pymysql.install_as_MySQLdb()
第三步、在应用程序目录下面的models.py文件中写对应的类,这里为创建一张表
from django.db import models
#这里表示创建一个userinfo表,需要注意的是,django在创建表的时候会把表名小写并重命名为 应用程序_userinfo
class UserInfo(models.Model):
id = models.AutoField(primary_key=True)
username = models.CharField(max_length=10)
password = models.CharField(max_length=32)
第四步: 执行数据库同步指令,在终端中执行,执行的路径是django项目下
#在migrations文件夹下面生成记录文件
python3 manage.py makemigrations
#执行记录文件
python3 manage.py migrate
可以看到,我们自定义的表已经创建完成了,但是发现多了好多其他的表,那这些表是从哪来的呢,这些是django从settings文件中循环读取INSTALLED_APPS下的所有子项而默认创建的表
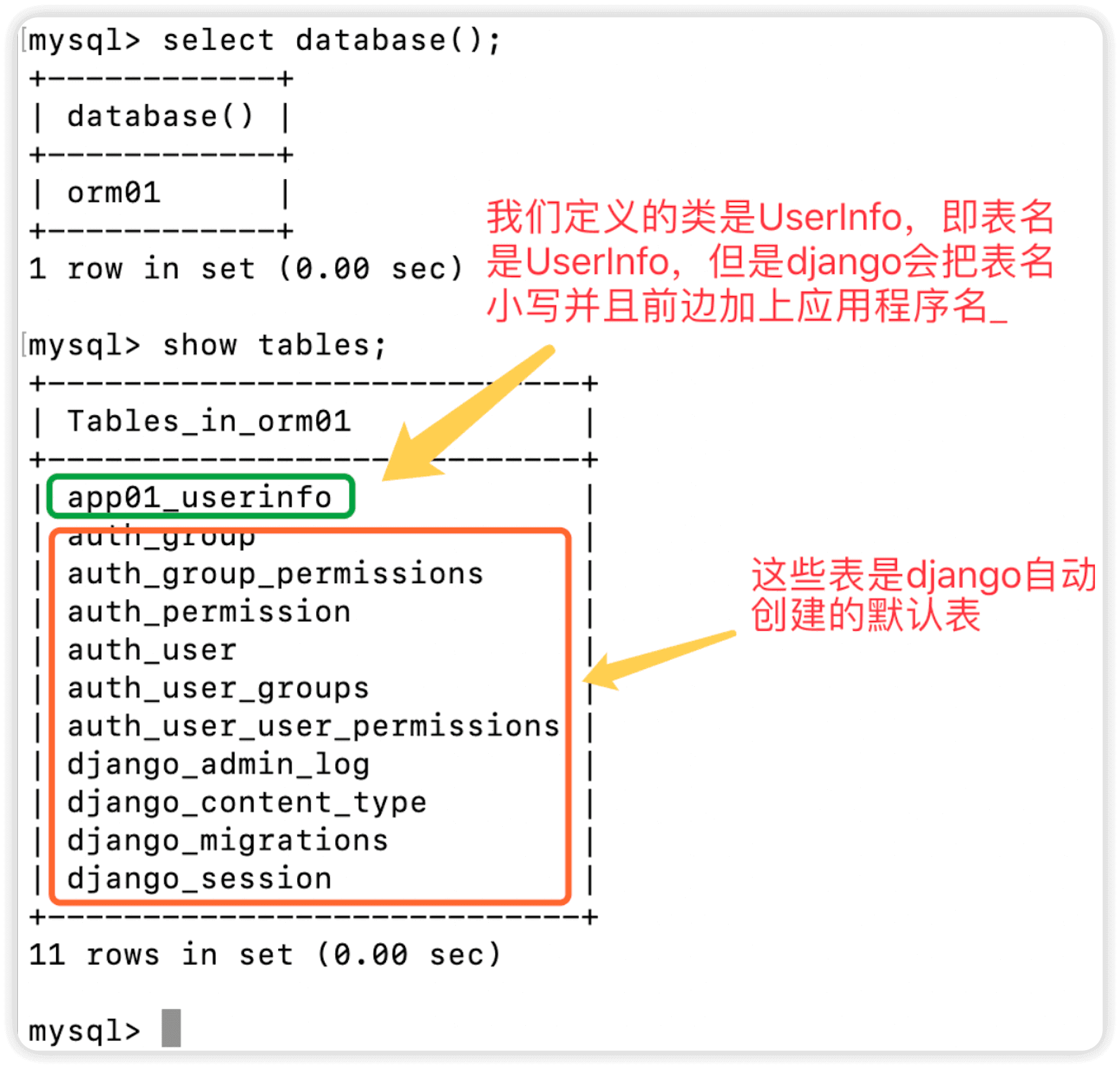
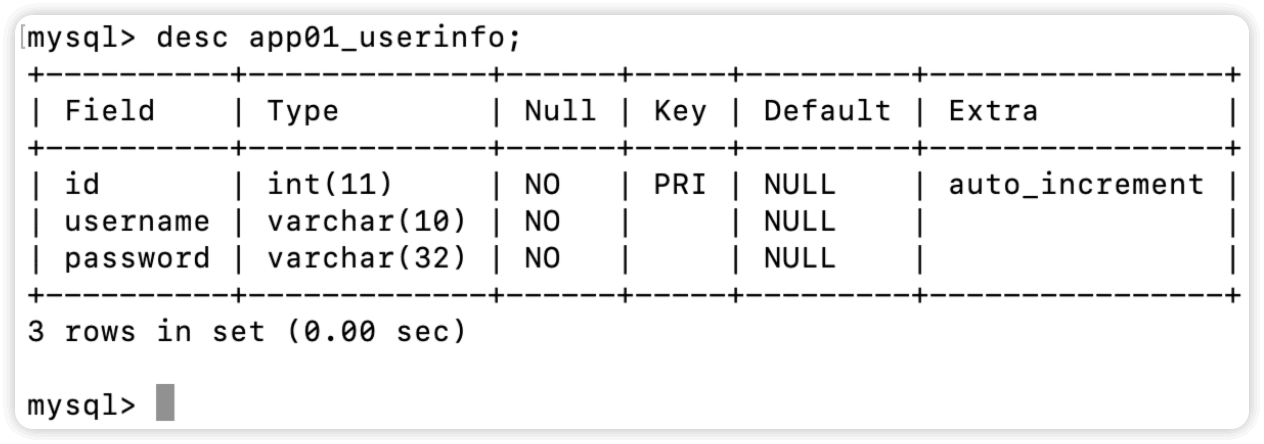
表结构
5.2.2 单表操作
5.2.2.1 增
应用程序的models.py文件中已经定义了创建一张表的语句
urls文件
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^index/', views.index),
]
views文件
from django.shortcuts import render,HttpResponse
from app01 import models
#方式1
def index(request):
obj = models.UserInfo(
username='小明',
password='123'
)
obj.save()
return HttpResponse('ok')
#方式2
def index(request):
models.UserInfo.objects.create(
username='小颖',
password='666'
)
return HttpResponse('ok')
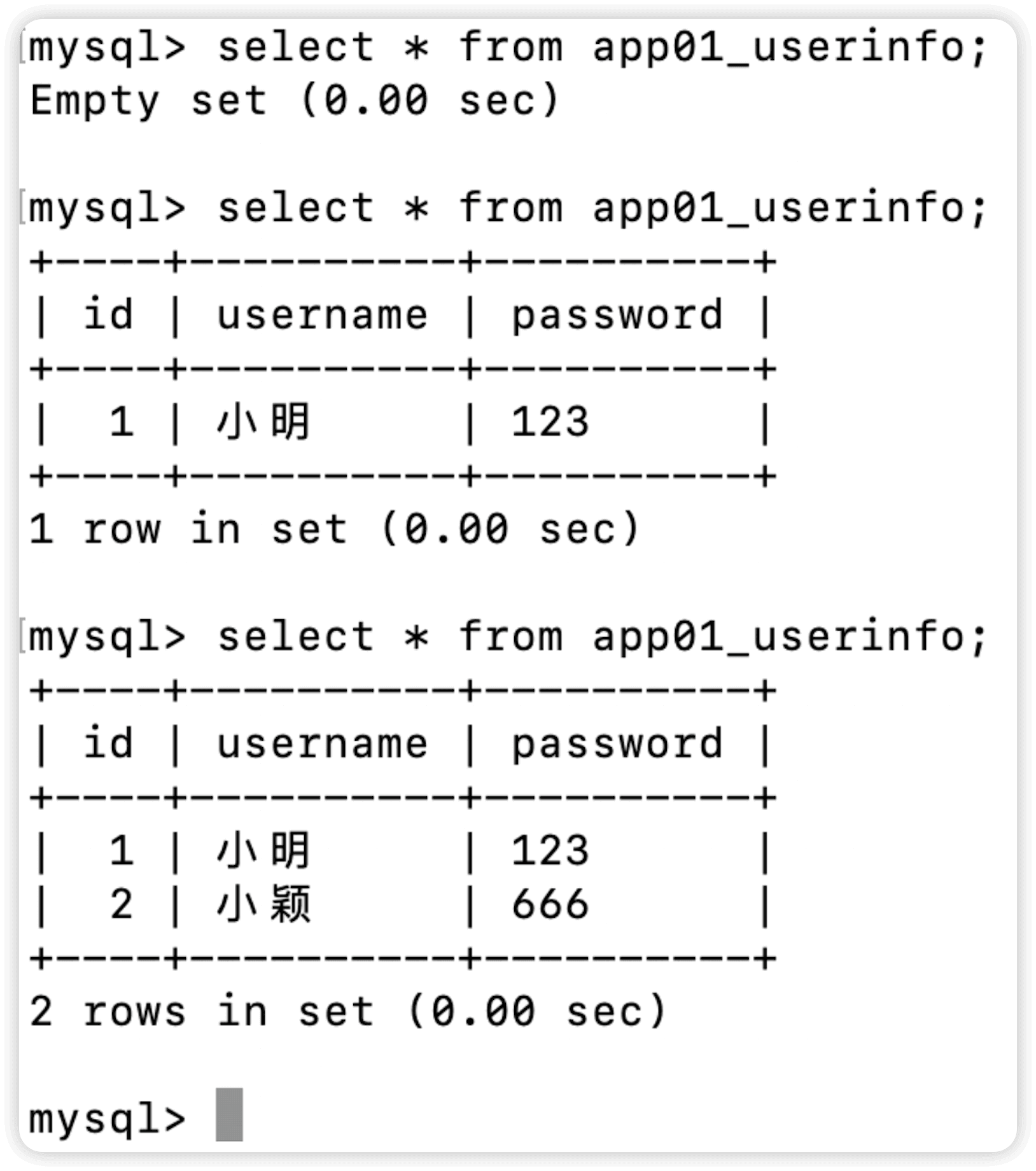
接下来启动django项目,浏览器访问我们指定的127.0.0.1:8000/index
执行以上任意一种方式都可以插入数据
5.2.2.2 删
views文件
def index(request):
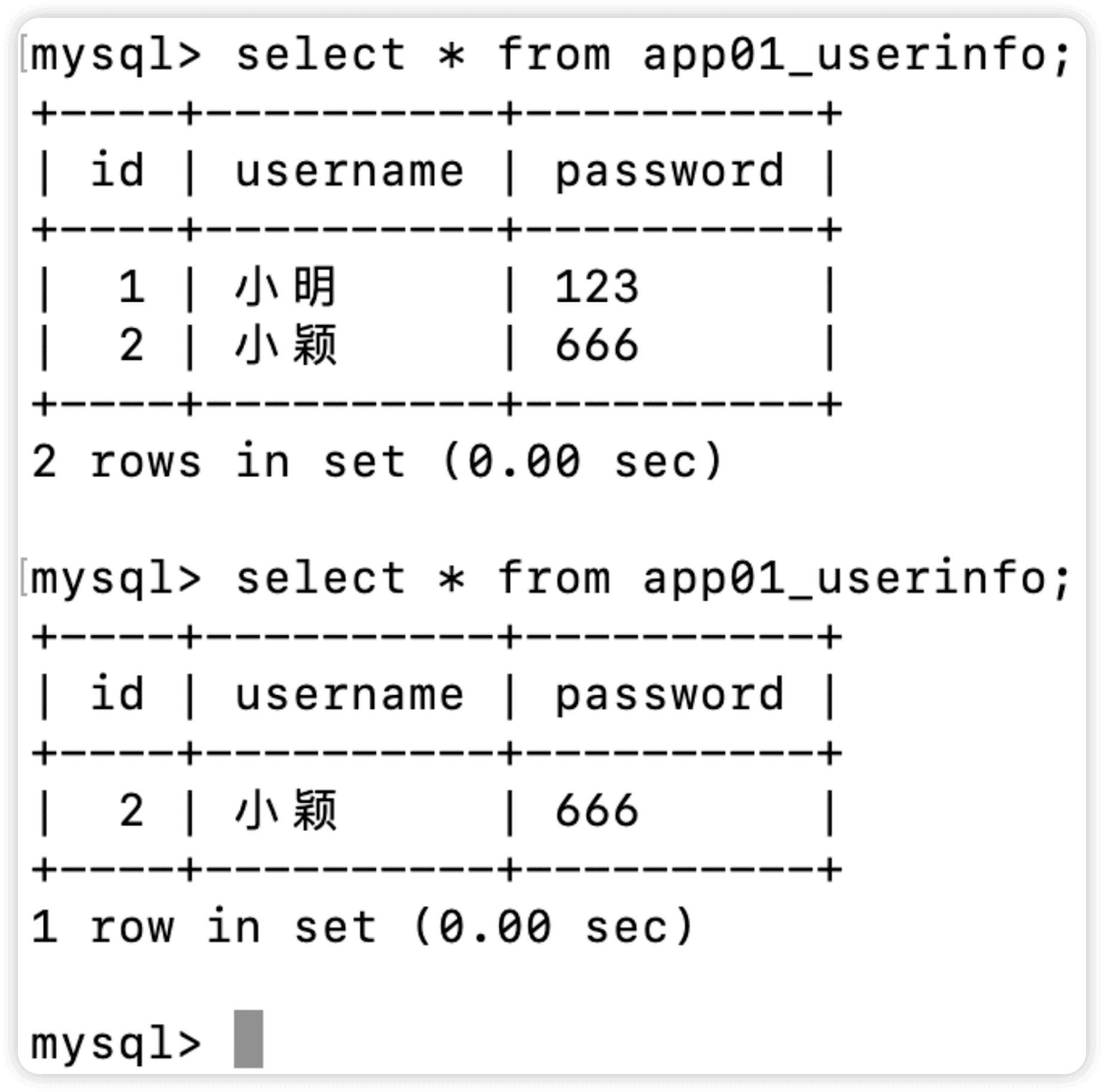
#删除UserInfo表中id值为1的值
models.UserInfo.objects.filter(id=1).delete()
return HttpResponse('ok')
浏览器访问127.0.0.1/index即可成功执行语句
可以看到,id为1的字段已经被删除
5.2.2.3 改
views文件
from django.shortcuts import render,HttpResponse
from app01 import models
# Create your views here.
def index(request):
# 方式1
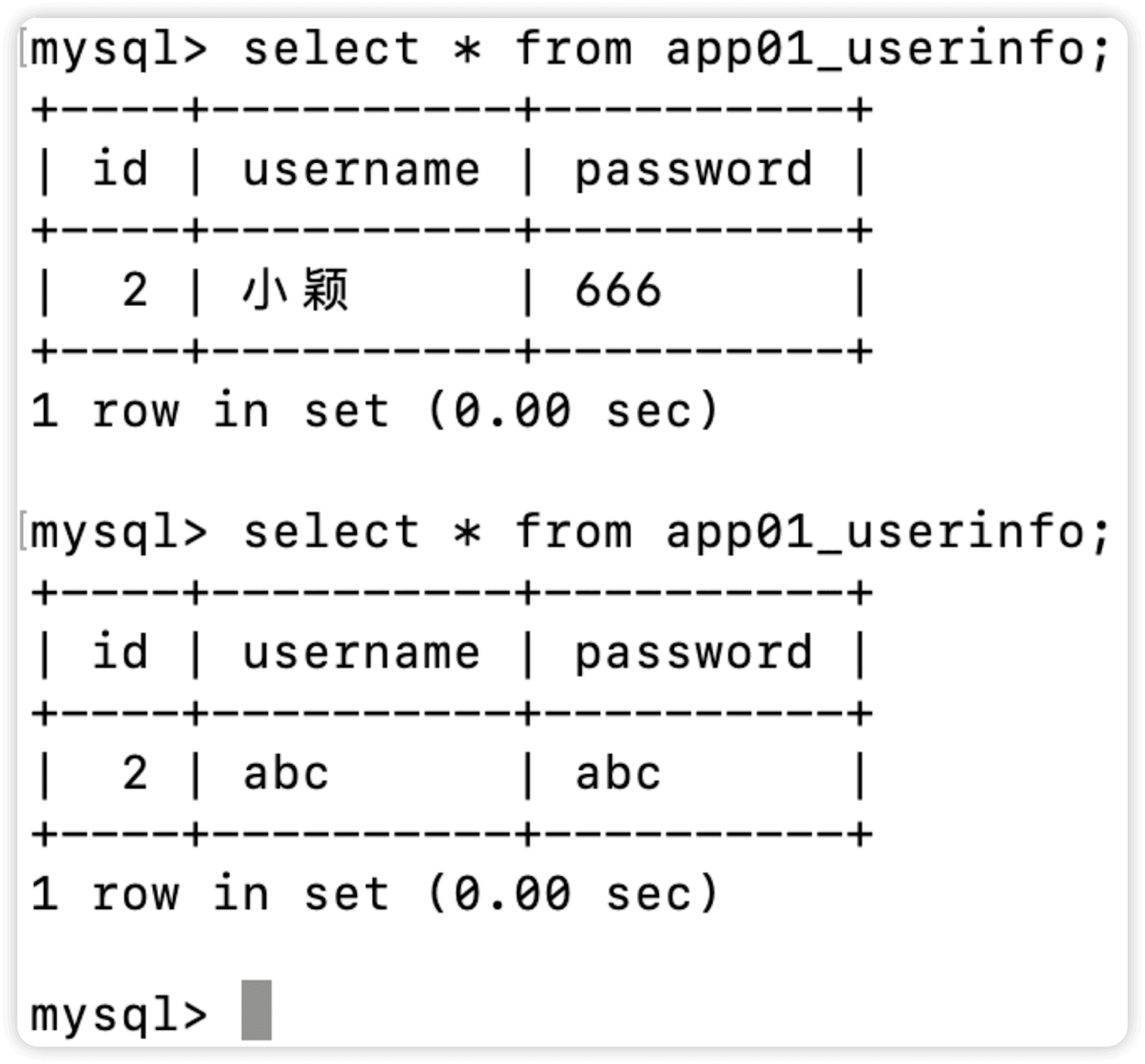
models.UserInfo.objects.filter(id=2).update(
username='abc',
password='abc',
)
# 方式2
# obj = models.UserInfo.objects.filter(id=2)[0]
# obj.username = 'ggg'
# obj.password = 'ggg'
# obj.save()
return HttpResponse('ok')
浏览器访问127.0.0.1/index
可以看到修改已经生效
批量创建
views文件
from django.shortcuts import render,HttpResponse
from app01 import models
# Create your views here.
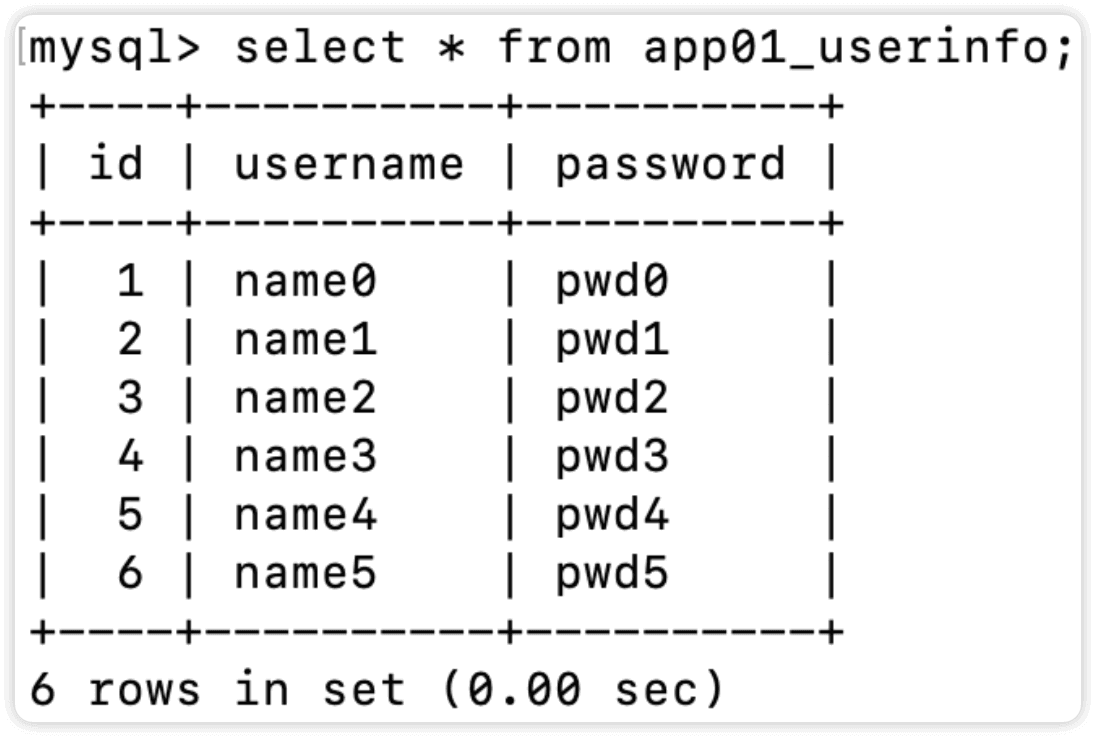
def index(request):
list_obj = []
for i in range(6):
obj = models.UserInfo(
username='name%s' %i,
password='pwd%s' %i,
)
list_obj.append(obj)
print(list_obj)
models.UserInfo.objects.bulk_create(list_obj)
return HttpResponse('ok')
print(list_obj)返回的结果如下
[<UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>, <UserInfo: UserInfo object>]
浏览器访问127.0.0.1/index
可以看到已经批量插入了数据
update_or_create 有就更新,没有就创建
from django.shortcuts import render,HttpResponse
from app01 import models
# Create your views here.
def index(request):
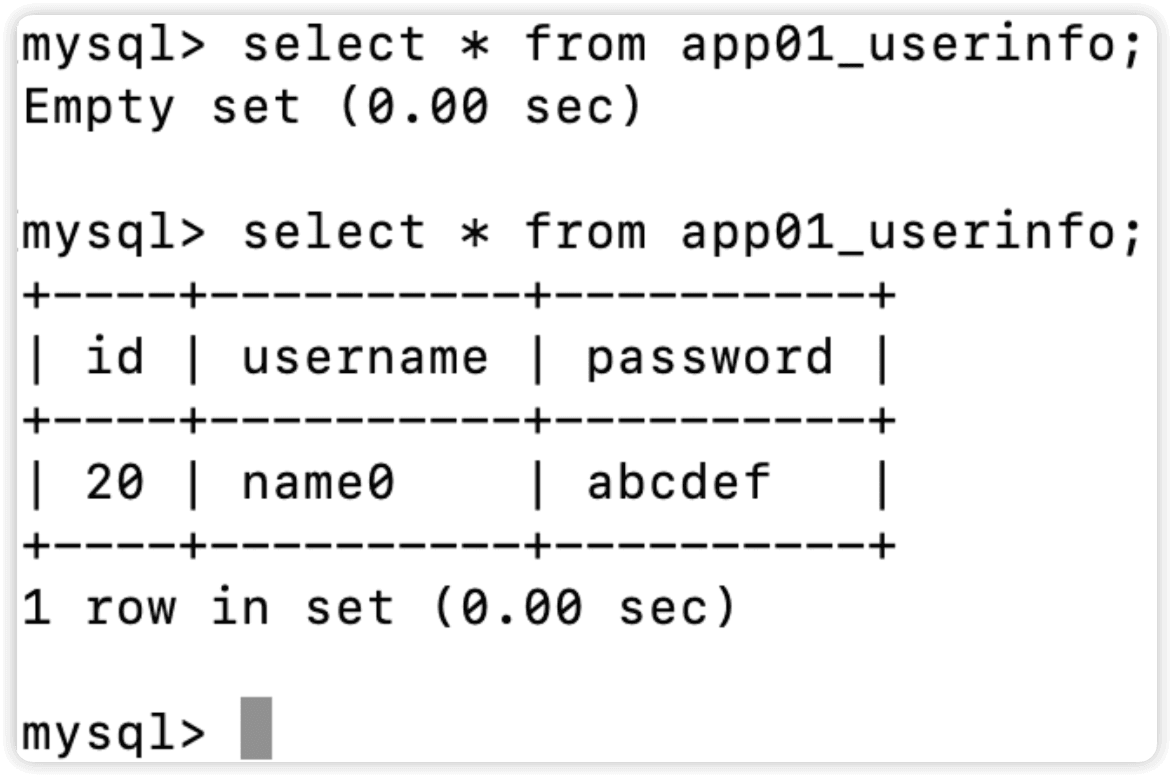
a,b = models.UserInfo.objects.update_or_create(
username='name0',
defaults={
'id': 20,
'password': 'abcdef',
}
)
print(a) #当前更新后的model对象,或者是你新增的记录的model对象
print(b) #新增就是True,查询就False
return HttpResponse('ok')
#a返回的结果
UserInfo object
#b返回的结果
True
5.2.2.4 查
最简单的查询
from django.shortcuts import render,HttpResponse
from app01 import models
# Create your views here.
def index(request):
ret = models.UserInfo.objects.filter(id=1)
print(ret) # <QuerySet [<UserInfo: UserInfo object>]> -- []
obj = ret[0]
print(obj.id, obj.username)
return HttpResponse('ok')
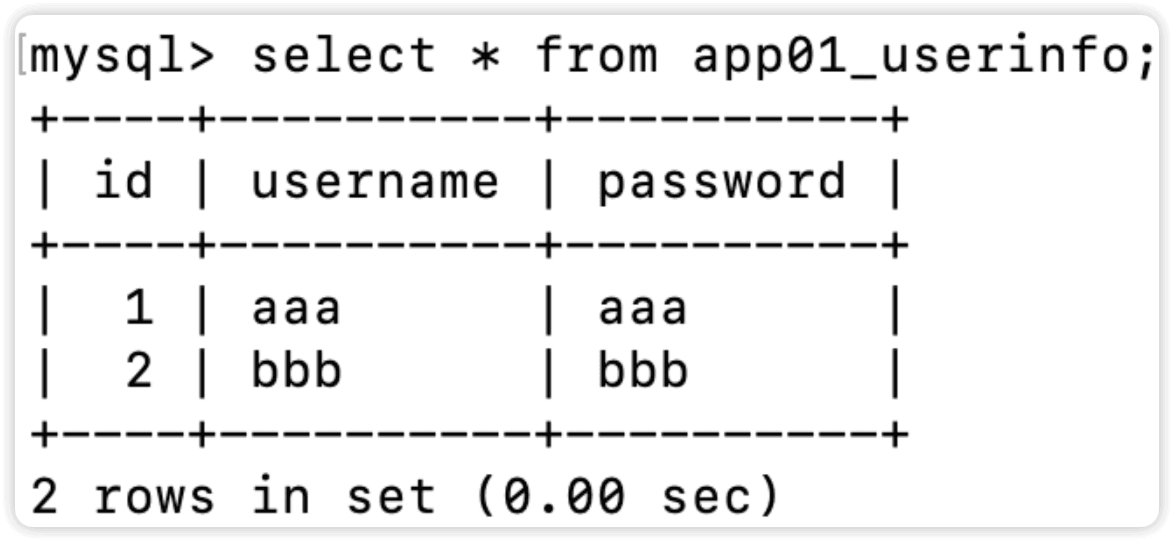
表app01_userinfo内容如下
print(ret)结果如下
<QuerySet [<UserInfo: UserInfo object>]>
print(obj.id, obj.username)执行后结果如下
1 aaa
查询非常重要的13种方法
1 all() 查询所有结果,结果是queryset类型
views文件
from django.shortcuts import render,HttpResponse
from app01 import models
# Create your views here.
def index(request):
ret = models.UserInfo.objects.all()
print(ret)
return HttpResponse('ok')
#print(ret)结果如下
<QuerySet [<UserInfo: UserInfo object>, <UserInfo: UserInfo object>]>
现在我们想看到的是数据库中的数据,需要在models文件中我们创建的UserInfo中写一个类的属性
class UserInfo(models.Model):
id = models.AutoField(primary_key=True)
username = models.CharField(max_length=10)
password = models.CharField(max_length=32)
#在models文件中写上这个属性后就能在all()方法中返回数据而不是对戏那个
def __str__(self):
return self.username
#结果如下
<QuerySet [<UserInfo: aaa>, <UserInfo: bbb>]>
2 get() 只能返回一个数据,没有或者数据多就报错,不是queryset类型,是行记录对象
例如,查询一个表中密码为aaa的数据,如果这个表中只有一个用户的密码是aaa,则可以查询成功,如果这个表中有多个用户的密码是aaa这个时候就会报错并且这个表中如果没有用户的密码是aaa同样会报错
from django.shortcuts import render,HttpResponse
from app01 import models
# Create your views here.
def index(request):
ret = models.UserInfo.objects.get(password='aaa')
print(ret)
return HttpResponse('ok')
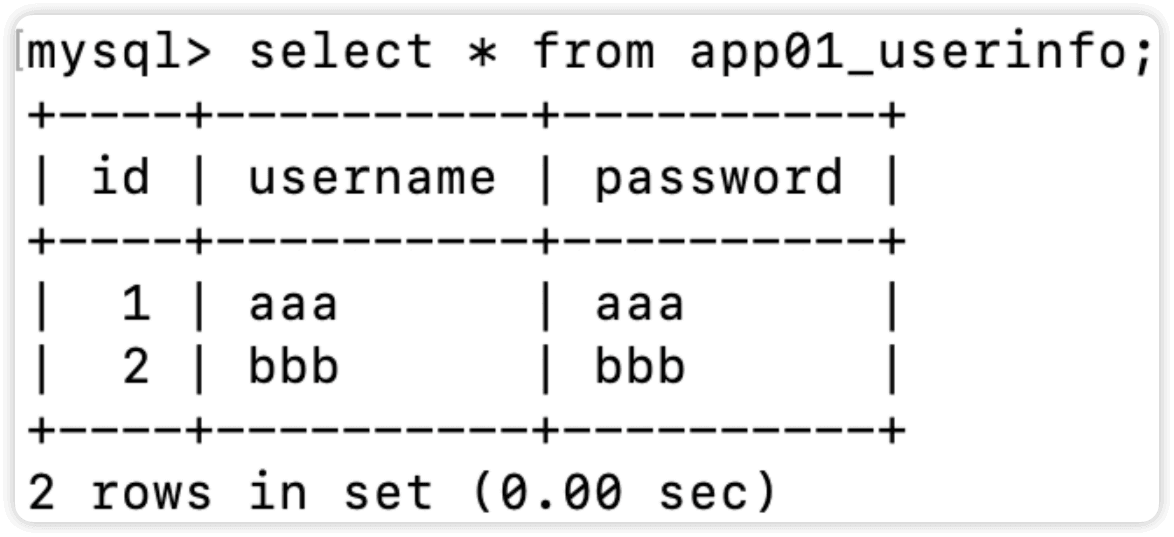
表app01_userinfo内容如下
浏览器访问127.0.0.1/index
此时返回的结果是可以成功查询的
现在修改表内容如下
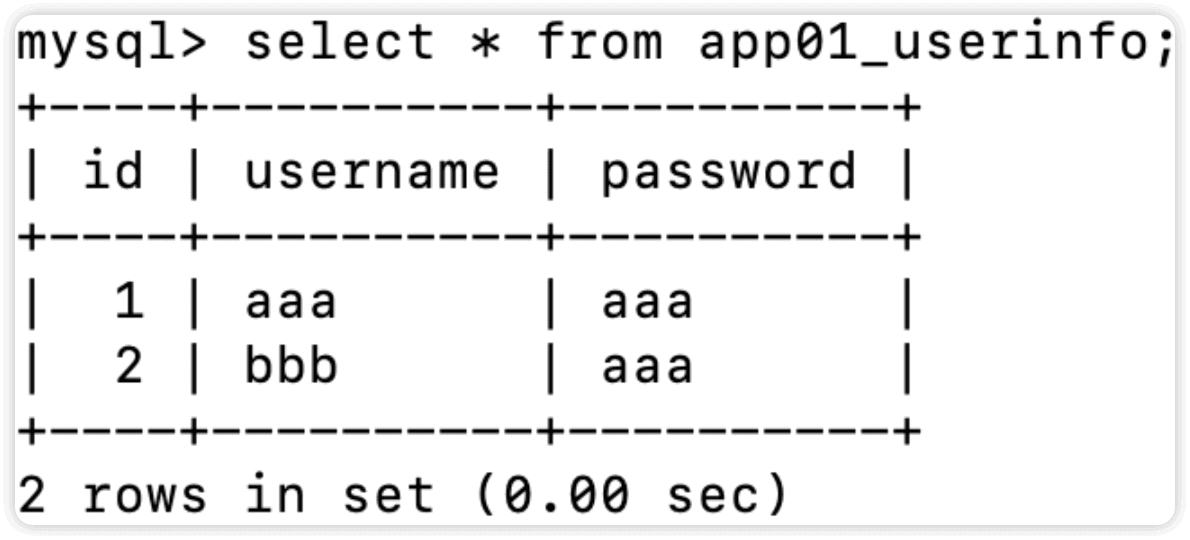
再次执行以上代码,查询表中密码为aaa的数据,此时会报错
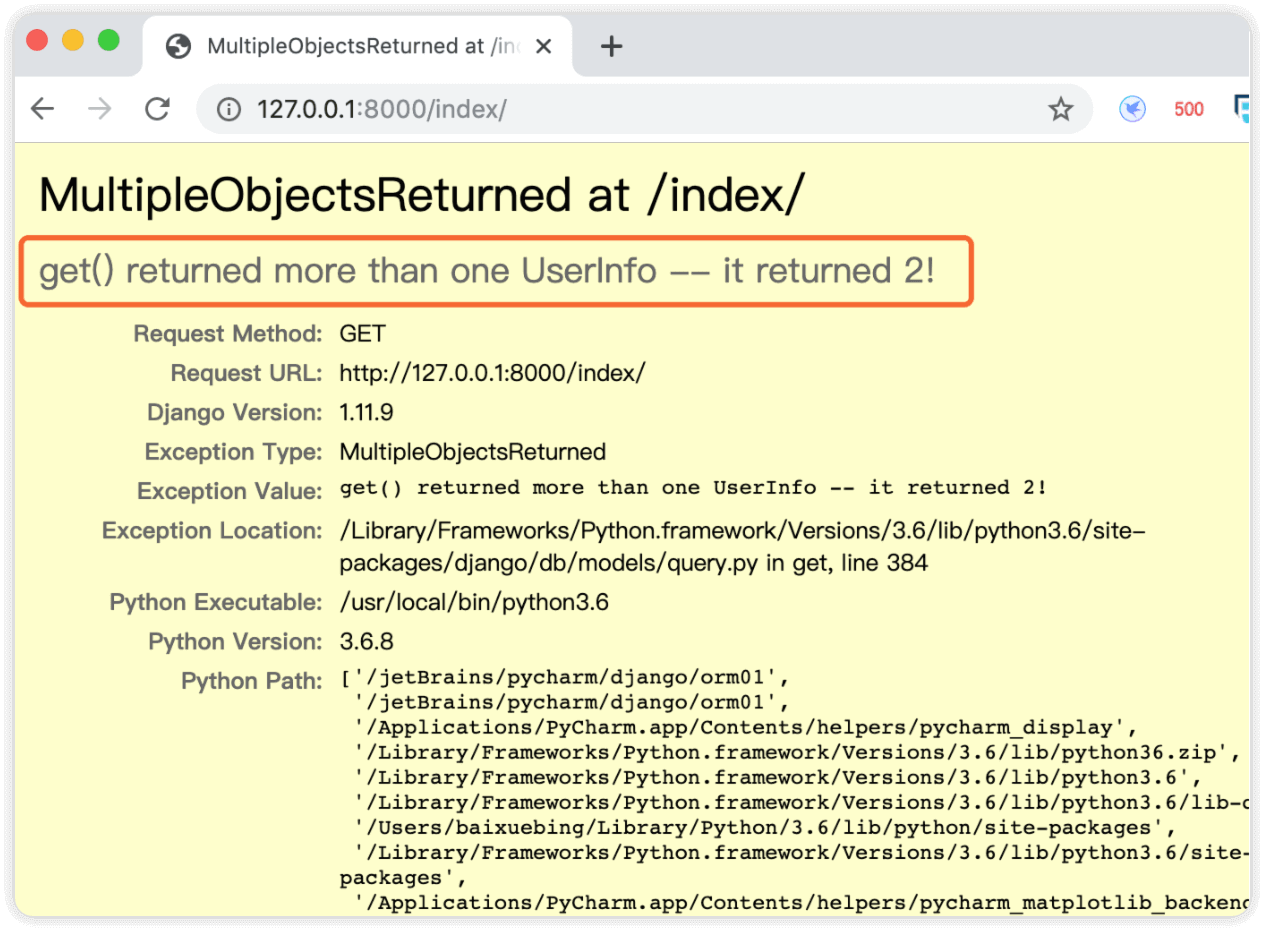
修改代码为查询表中密码为bbb的数据,同样会报错
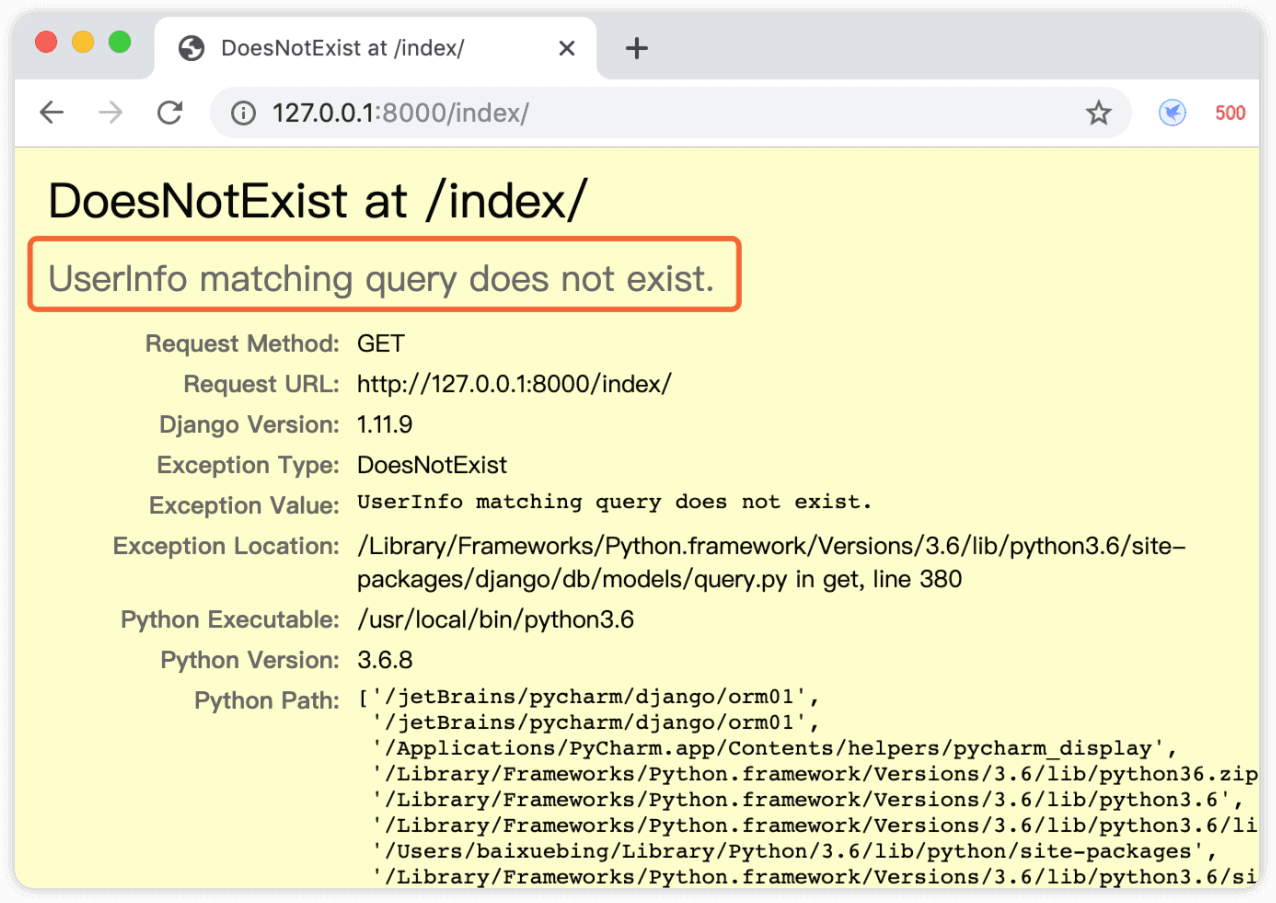
get两个报错,但是get请求返回的结果是model对象
#1.UserInfo matching query does not exist. 没有查到的报错
#2 get() returned more than one UserInfo -- it returned 11! 结果多了,不行!
3 filter() 查询数据,返回值是queryset类型
views文件
from django.shortcuts import render,HttpResponse
from app01 import models
# Create your views here.
def index(request):
ret = models.UserInfo.objects.filter(password='bbb')
print(ret)
return HttpResponse('ok')
filter查询表中密码为bbb的数据,虽然表中结果没有,但是不会像get报错
print(ret)结果如下
<QuerySet []>
filter查询表中密码为aaa的数据,表中密码为aaa的数据有2条,filter不会像get一样报错
<QuerySet [<UserInfo: aaa>, <UserInfo: bbb>]>
4 exclude() 排除,返回值是queryset类型
现有app01_book表如下
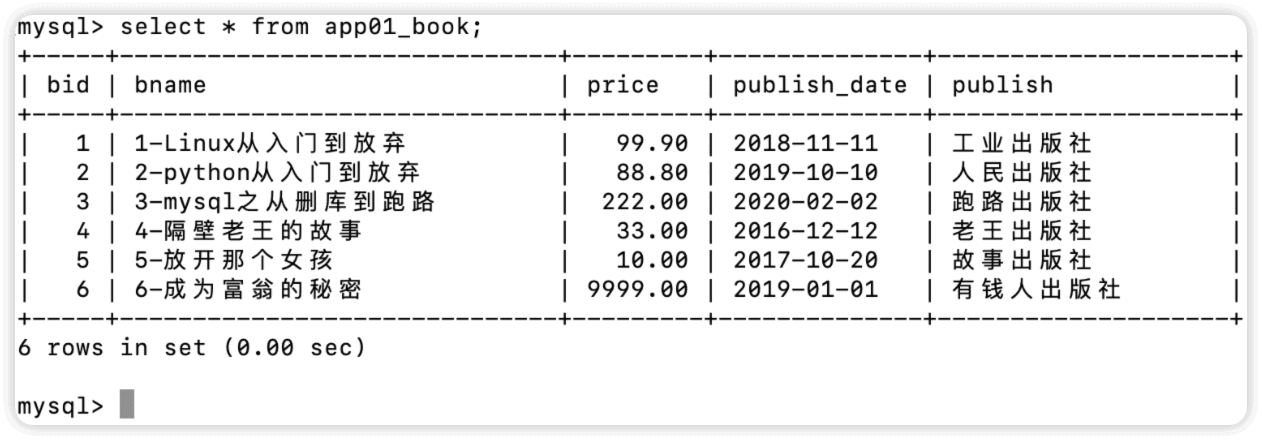
查询所有数据,排除bid为4的数据
urls文件
from django.conf.urls import url,include
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^index/', views.index),
]
views文件
from django.shortcuts import render,reverse,redirect,HttpResponse
from app01 import models
def index(request):
#查询bid不为4的数据,这里还可以写多个排除条件,以逗号分隔
ret = models.Book.objects.exclude(bid=4)
print(ret)
return HttpResponse('ok')
models文件
class Book(models.Model):
bid = models.AutoField(primary_key=True)
bname = models.CharField(max_length=20)
price = models.DecimalField(max_digits=6,decimal_places=2)
publish_date = models.DateField(auto_now_add=False)
publish = models.CharField(max_length=20)
def __str__(self):
return self.bname
浏览器访问127.0.0.1/index,返回结果如下,bid为4的隔壁老王的故事没有返回
<QuerySet [<Book: 1-Linux从入门到放弃>, <Book: 2-python从入门到放弃>, <Book: 3-mysql之从删库到跑路>, <Book: 5-放开那个女孩>, <Book: 6-成为富翁的秘密>]>
5 order_by() queryset类型的数据来调用,对查询结果排序,默认是按照id来升序排列的,返回值是queryset类型
按照bid倒序排序,在bid前加个-号即可
viwes文件
def index(request):
ret = models.Book.objects.all().order_by('-bid')
print(ret)
return HttpResponse('ok')
浏览器反问127.0.0.1/index,返回结果如下,结果是倒序
<QuerySet [<Book: 6-成为富翁的秘密>, <Book: 5-放开那个女孩>, <Book: 4-隔壁老王的故事>, <Book: 3-mysql之从删库到跑路>, <Book: 2-python从入门到放弃>, <Book: 1-Linux从入门到放弃>]>
order_by()中加多个条件说明
#这段代码的意思是按照id倒叙排序,然后再按照id相同的数据进行价格升序排序
models.Test.objects.all().order_by('-id','money')
现有表app01_test如下
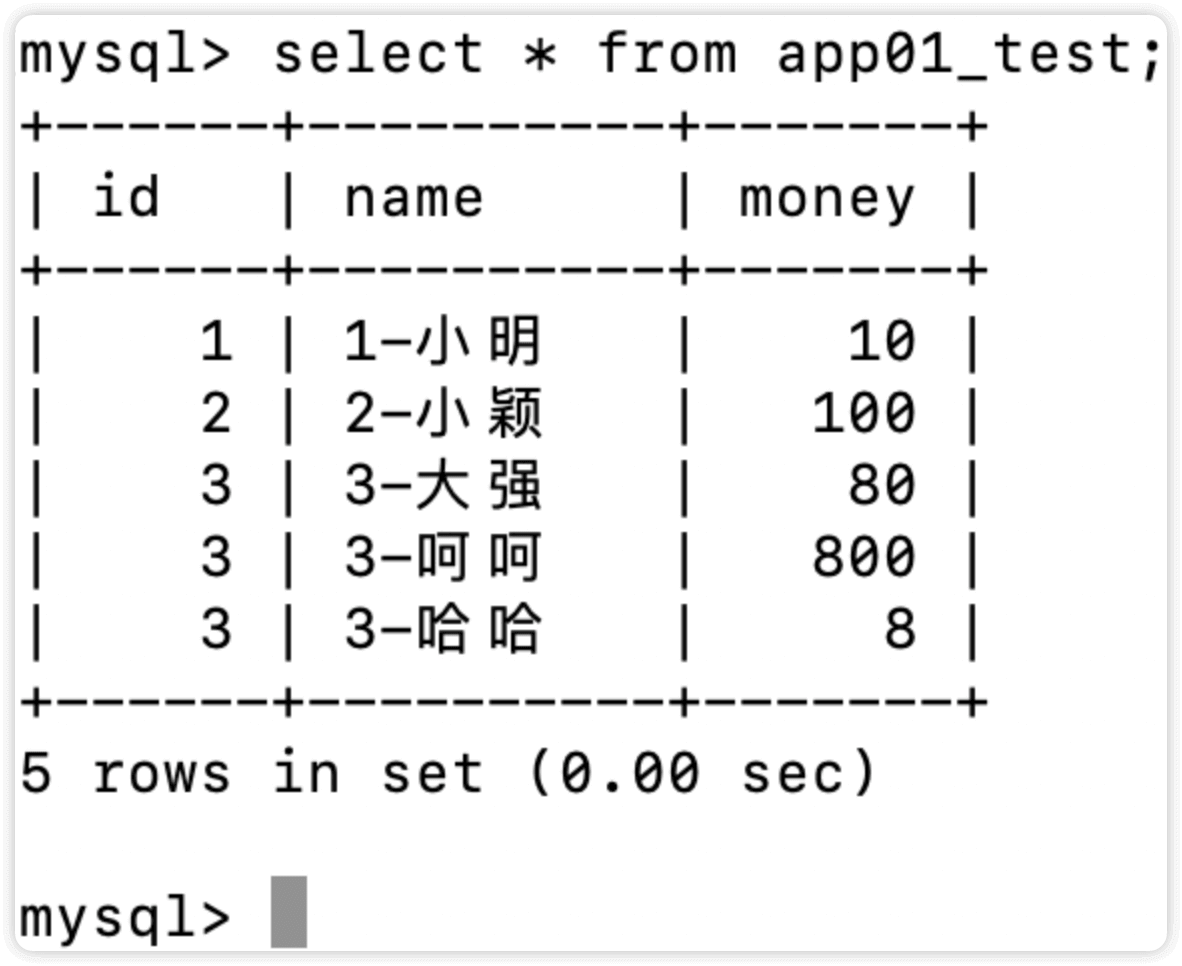
先按照id进行倒叙排序
ret = models.Test.objects.all().order_by('-id')
print(ret.values())
返回结果如下
<QuerySet [{'id': 3, 'name': '3-哈哈', 'money': 8}, {'id': 3, 'name': '3-大强', 'money': 80}, {'id': 3, 'name': '3-呵呵', 'money': 800}, {'id': 2, 'name': '2-小颖', 'money': 100}, {'id': 1, 'name': '1-小明', 'money': 10}]>
再加一个条件进行排序,先根据id相同的进行倒序排序,然后再根据money升序排序
ret = models.Test.objects.order_by('-id','money')
print(ret.values())
返回结果如下
<QuerySet [{'id': 3, 'name': '3-大强', 'money': 80}, {'id': 3, 'name': '3-呵呵', 'money': 800}, {'id': 3, 'name': '3-哈哈', 'money': 8}, {'id': 2, 'name': '2-小颖', 'money': 100}, {'id': 1, 'name': '1-小明', 'money': 10}]>
6 reverse() queryset类型的数据来调用,对查询结果反向排序,返回值还是queryset类型
以例5中app01_test表为例
⚠️直接进行reverse进行反向排序是不生效的,必须先进行分组
ret = models.Test.objects.all().reverse()
返回结果如下,不分组进行反向排序是不生效的
<QuerySet [{'id': 1, 'name': '1-小明', 'money': 10}, {'id': 2, 'name': '2-小颖', 'money': 100}, {'id': 3, 'name': '3-大强', 'money': 80}, {'id': 3, 'name': '3-呵呵', 'money': 800}, {'id': 3, 'name': '3-哈哈', 'money': 8}]>
先进行分组,然后再进行反向排序才能生效
ret = models.Test.objects.all().order_by('id').reverse()
返回结果如下
<QuerySet [{'id': 3, 'name': '3-大强', 'money': 80}, {'id': 3, 'name': '3-呵呵', 'money': 800}, {'id': 3, 'name': '3-哈哈', 'money': 8}, {'id': 2, 'name': '2-小颖', 'money': 100}, {'id': 1, 'name': '1-小明', 'money': 10}]>
7 count() queryset类型的数据来调用,返回数据库中匹配查询(QuerySet)的对象数量
以例5中app01_test表为例
ret = models.Test.objects.all().count()
print(ret)
返回结果�为5,因为app01_test表中有5条记录
8 first() queryset类型的数据来调用,返回第一条记录,得到的都是model对象,不是queryset
以例5中app01_test表为例
ret = models.Test.objects.all().first()
print(ret)
#models文件表的类中需要写如下代码
class Test(models.Model):
id = models.IntegerField(primary_key=True)
name = models.CharField(max_length=10)
money = models.IntegerField()
def __str__(self):
return self.name
返回结果为1-小明
9 last() queryset类型的数据来调用,返回最后一条记录,得到的是model对象
以例5中app01_test表为例
ret = models.Test.objects.all().last()
print(ret)
#models文件表的类中需要写如下代码
class Test(models.Model):
id = models.IntegerField(primary_key=True)
name = models.CharField(max_length=10)
money = models.IntegerField()
def __str__(self):
return self.name
查询时遇到的一个问题,使用last方法查询一个没有设置主键的表时,只能返回id相同的记录中的第一个id的记录
例如,一张表中id字段如下:1、2、3、3、3,查询的返回的结果是id=3的第一条记录,即2后边的第一个3
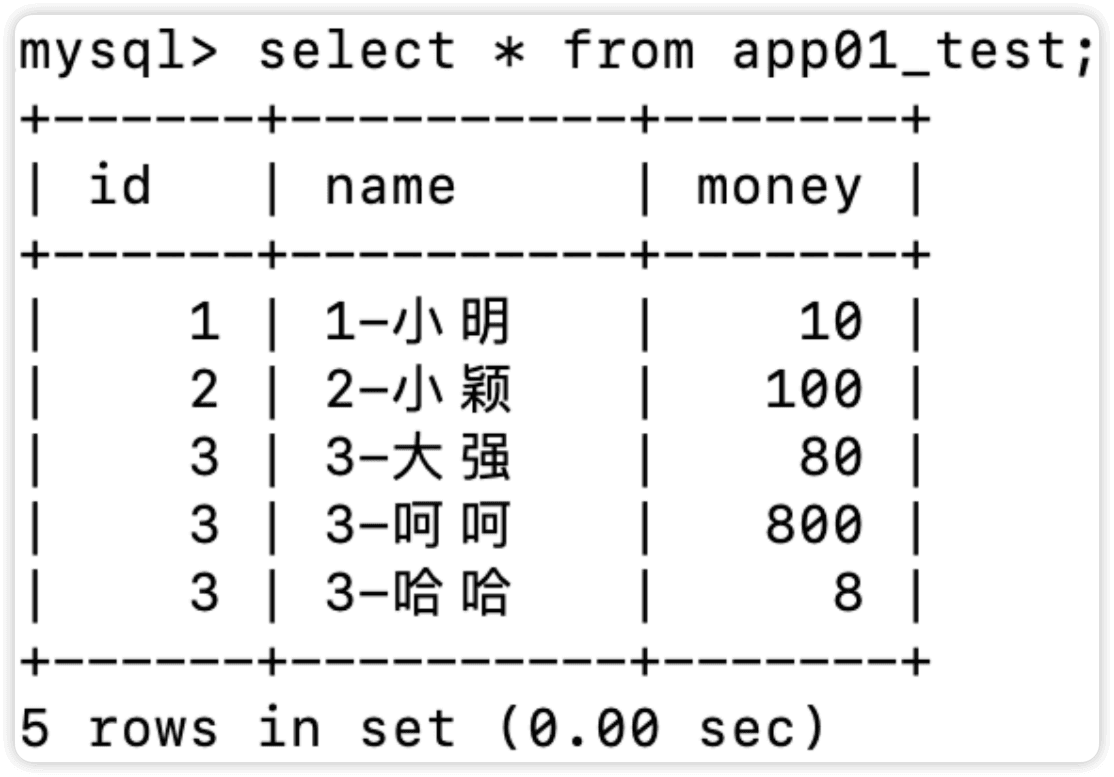
此表中没有设置主键,只能返回3-大强,而理论上是3-哈哈
10 exists() queryset类型的数据来调用,如果QuerySet包含数据,就返回True,否则返回False
空的queryset类型数据也有布尔值True和False,但是一般不用它来判断数据库里面是不是有数据,如果有大量的数据,你用它来判断,那么就需要查询出所有的数据,效率太差了,用count或者exits 例:all_books = models.Book.objects.all().exists() #翻译成的sql是SELECT (1) AS
aFROMapp01_bookLIMIT 1,就是通过limit 1,取一条来看看是不是有数据
以例5中app01_test表为例
test表中没有id=5的数据,因此会返回False
ret = models.Test.objects.filter(id=5).exists()
11 values() 用的比较多,queryset类型的数据来调用,返回一ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列,只要是返回的queryset类型,就可以继续连续调用queryset类型的其他的查找方法,其他方法也是一样的。
以例5中app01_test表为例
ret = models.UserInfo.objects.all().values('id','name') queryset调用
ret = models.UserInfo.objects.values('id','name') objects调用--对所有数据进行取值
返回结果如下
<QuerySet [{'id': 1, 'name': '1-小明'}, {'id': 2, 'name': '2-小颖'}, {'id': 3, 'name': '3-大强'}, {'id': 3, 'name': '3-呵呵'}, {'id': 3, 'name': '3-哈哈'}]>
12 values_list 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
以例5中app01_test表为例
ret = models.Test.objects.all().values_list('id','name')
返回结果如下
<QuerySet [(1, '1-小明'), (2, '2-小颖'), (3, '3-大强'), (3, '3-呵呵'), (3, '3-哈哈')]>
13 distinct() values和values_list得到的queryset类型的数据来调用,从返回结果中剔除重复纪录
以例5中app01_test表为例
ret = models.UserInfo.objects.all().values('id','name').distinct()
ret = models.UserInfo.objects.values('id','name').distinct()
基于双下划线的模糊查询
表app01_book内容如下
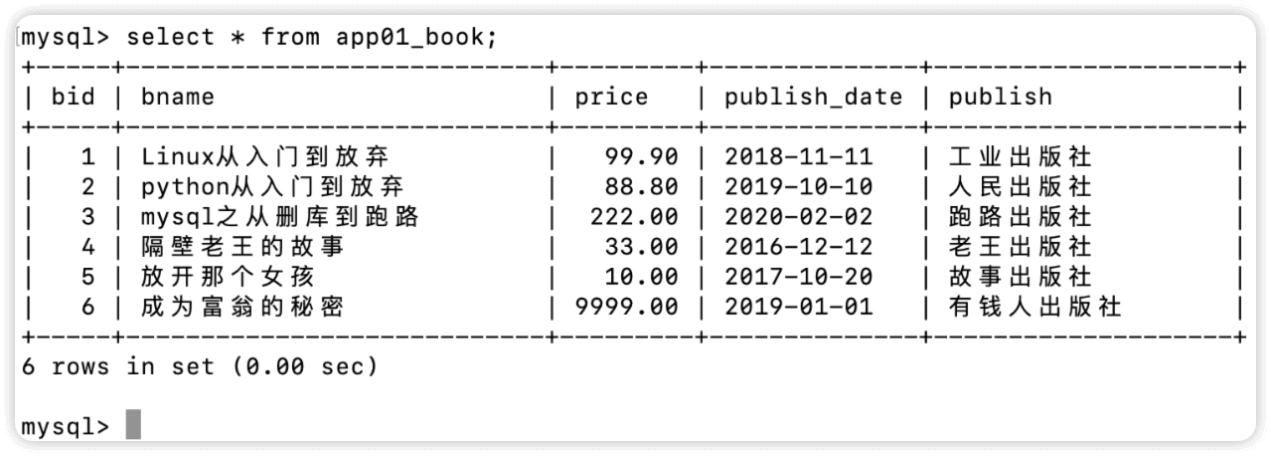
#price值等于这三个里面的任意一个的对象
Book.objects.filter(price__in=[10,33,9999])
#大于,大于等于是price__gte=100,别写price>100,这种参数不支持
Book.objects.filter(price__gt=100)
#小于,小于等于是price__lte=100,别写price<100,这种参数不支持
Book.objects.filter(price__lt=100)
#sql的between and,大于等于100,小于等于10000
Book.objects.filter(price__range=[100,10000])
#bname值中包含python的
Book.objects.filter(bname__contains="python")
#不区分大小写,在前边加一个i就是不区分大小写,其余用法相同
Book.objects.filter(bname__icontains="python")
#以什么开头,istartswith 不区分大小写
Book.objects.filter(bname__startswith="py")
#查询publish_date是2020年的
Book.objects.filter(publish_date__year=2020)
查询示例
1 查询某某出版社出版过的价格大于100的书籍
ret = models.Book.objects.filter(price__gt=100,publish='老王出版社').values('bname')
2 查询2018年11月出版的所有以Li开头的书籍名称
ret = models.Book.objects.filter(bname__startswith='Linux',publish_date__year=2018,publish_date__month=11).values('bname')
3 查询价格为88,100或者9999的所有书籍名称及其出版社名称
ret = models.Book.objects.filter(price__in=[88,100,9999]).values('bname','publish')
4 查询价格在80到100之间的所有书籍名称及其价格
ret = models.Book.objects.filter(price__range=[80,100]).values('bname','price')
5 查询所有老王出版社出版的书籍的价格(从高到低排序,去重)
ret = models.Book.objects.filter(publish='老王出版社').values('price').order_by('-price').distinct()
5.2.3 多表操作
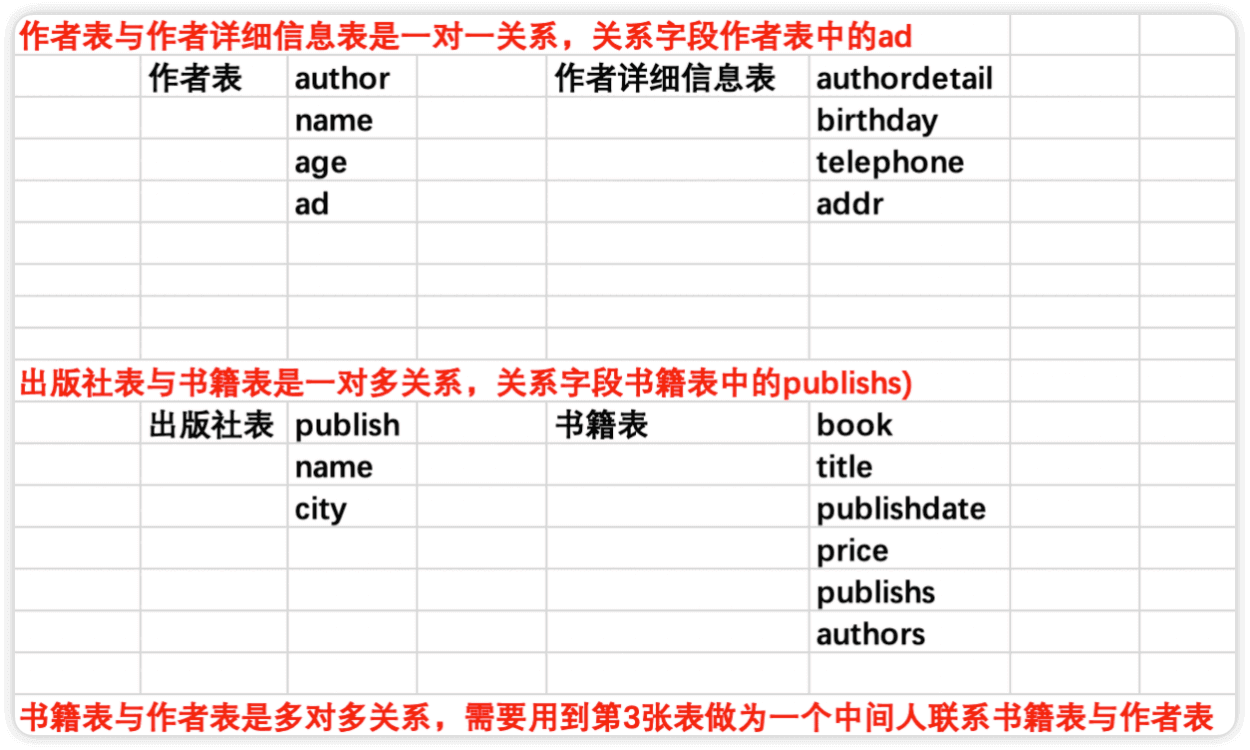
表关系及字段设计
urls文件
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^query/', views.query),
]
settings文件配置数据库连接
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'orm01',
'HOST': '127.0.0.1',
'PORT': '3306',
'USER': 'root',
'PASSWORD': 'xxx'
}
}
models文件
from django.db import models
# Create your models here.
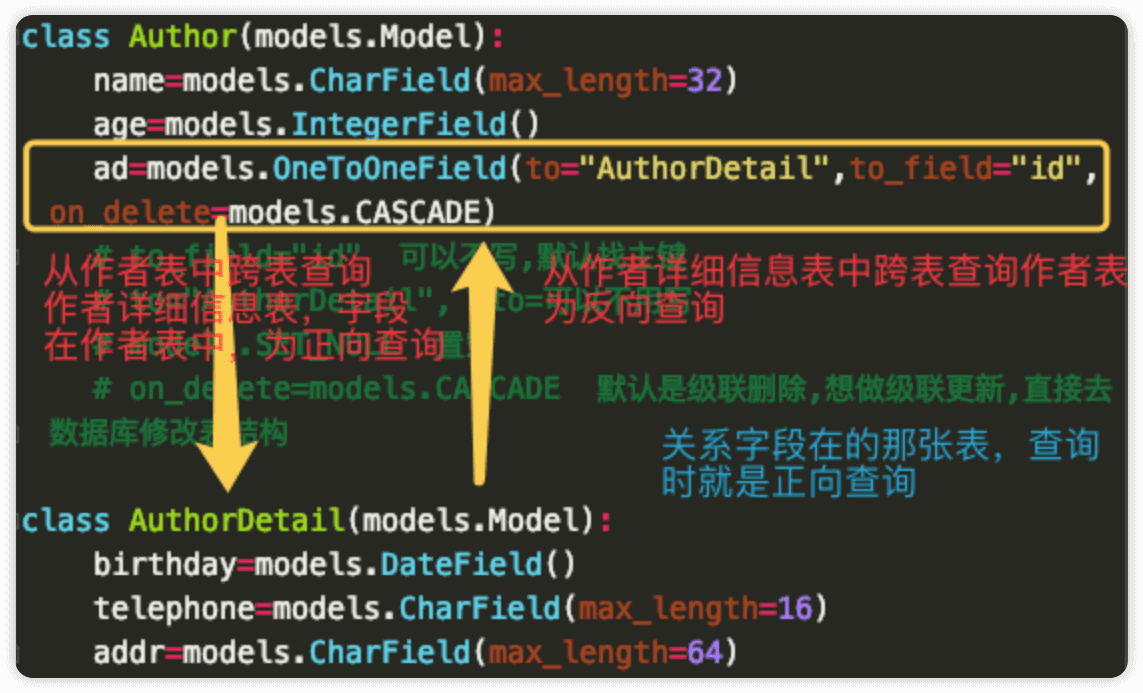
class Author(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
ad=models.OneToOneField(to="AuthorDetail",to_field="id",on_delete=models.CASCADE)
# to_field="id" 可以不写,默认找主键
# to="AuthorDetail", to=可以不用写
# models.SET_NULL 置空
# on_delete=models.CASCADE 默认是级联删除,想做级联更新,直接去数据库修改表结构
class AuthorDetail(models.Model):
birthday=models.DateField()
telephone=models.CharField(max_length=16)
addr=models.CharField(max_length=64)
class Publish(models.Model):
name=models.CharField(max_length=32)
city=models.CharField(max_length=32)
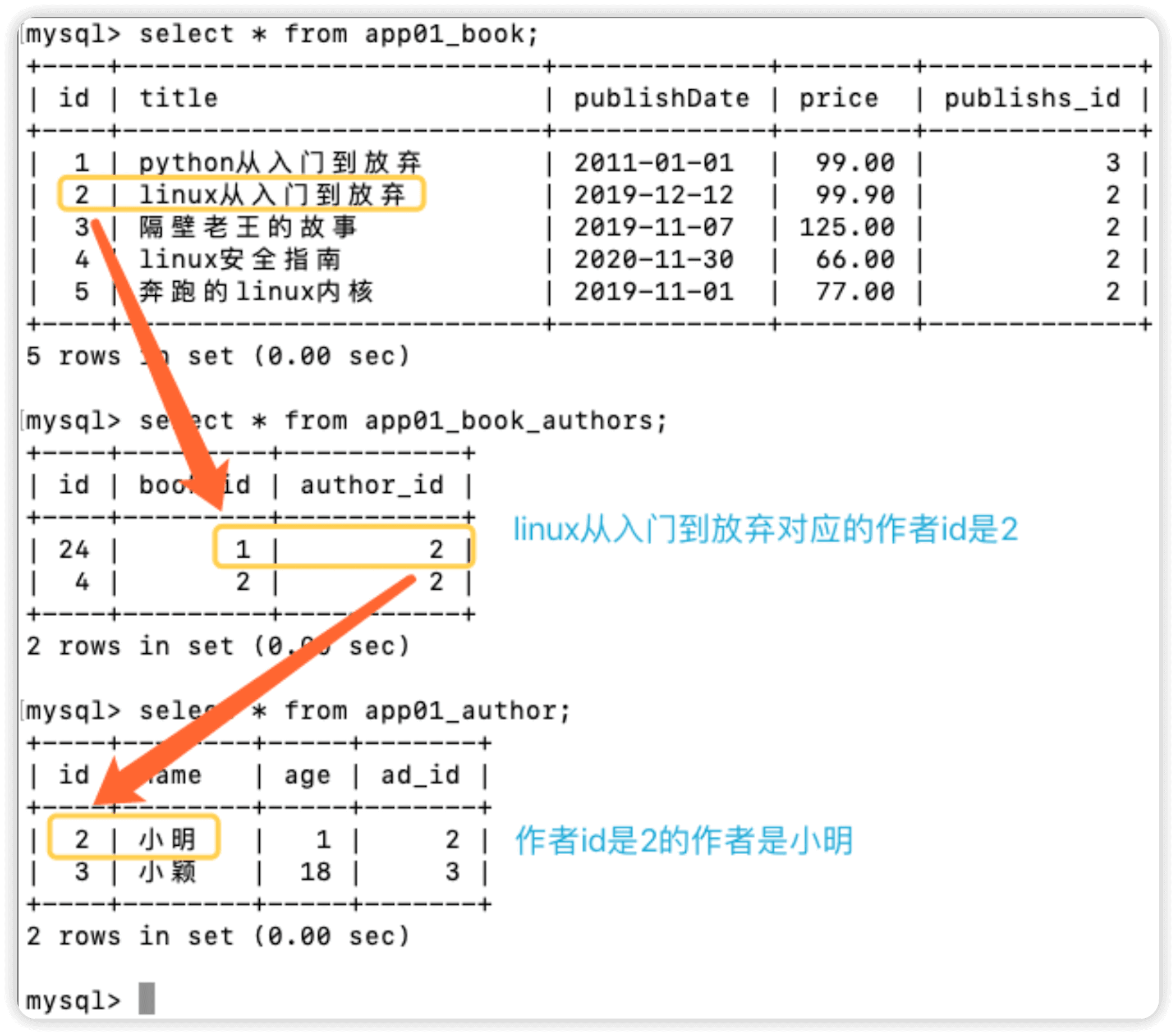
class Book(models.Model):
title = models.CharField(max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2)
publishs=models.ForeignKey(to="Publish",to_field="id",on_delete=models.CASCADE)
#这行代码的意思是生成第3张表关联book表和author表
authors=models.ManyToManyField(to='Author',)
⚠️如果AuthorDetail写在Author的上边,则ad=models.OneToOneField(to="AuthorDetail"中的AuthorDetail可以不加引号
⚠️django1.x版本on_delete=models.CASCADE可以不写,默认是级连删除,如果想做级连更新,直接到数据库中操作,但是django2.x必须写级连删除
⚠️OneToOneField是一对一 ForeignKey是一对多 ManyToManyField是多对多
django项目下同名目录__init__.py文件
import pymysql
pymysql.install_as_MySQLdb()
相关配置文件配置完成后开始同步数据库
⚠️makemigrations执行后必须执行migrate,否则会出问题
//在django项目下
#在migrations目录下面生成记录文件
python3 manage.py makemigrations
#执行记录文件
python3 manage.py migrate
关于只执行makemigrations不执行migrate可能出现的问题
1.当执行makemigrations后,会在django项目下的makemigrations目录中创建一个0001_initial.py,这个文件记录的是models文件中的操作(创建表、删除表),当执行migrate后会执行数据库同步操作,同时在数据库中django会自动创建一张django_migrations表,这个表记录的是models文件中的操作
2.如果只执行了makemigrations而不执行migrate,当修改了models文件再次重复执行makemigrations,django会从数据库中的django_migrations查看0001_initial是否执行过,而此时0001_initial已经执行过了,因此会出现修改了models文件执行migrate提示没有改动的问题
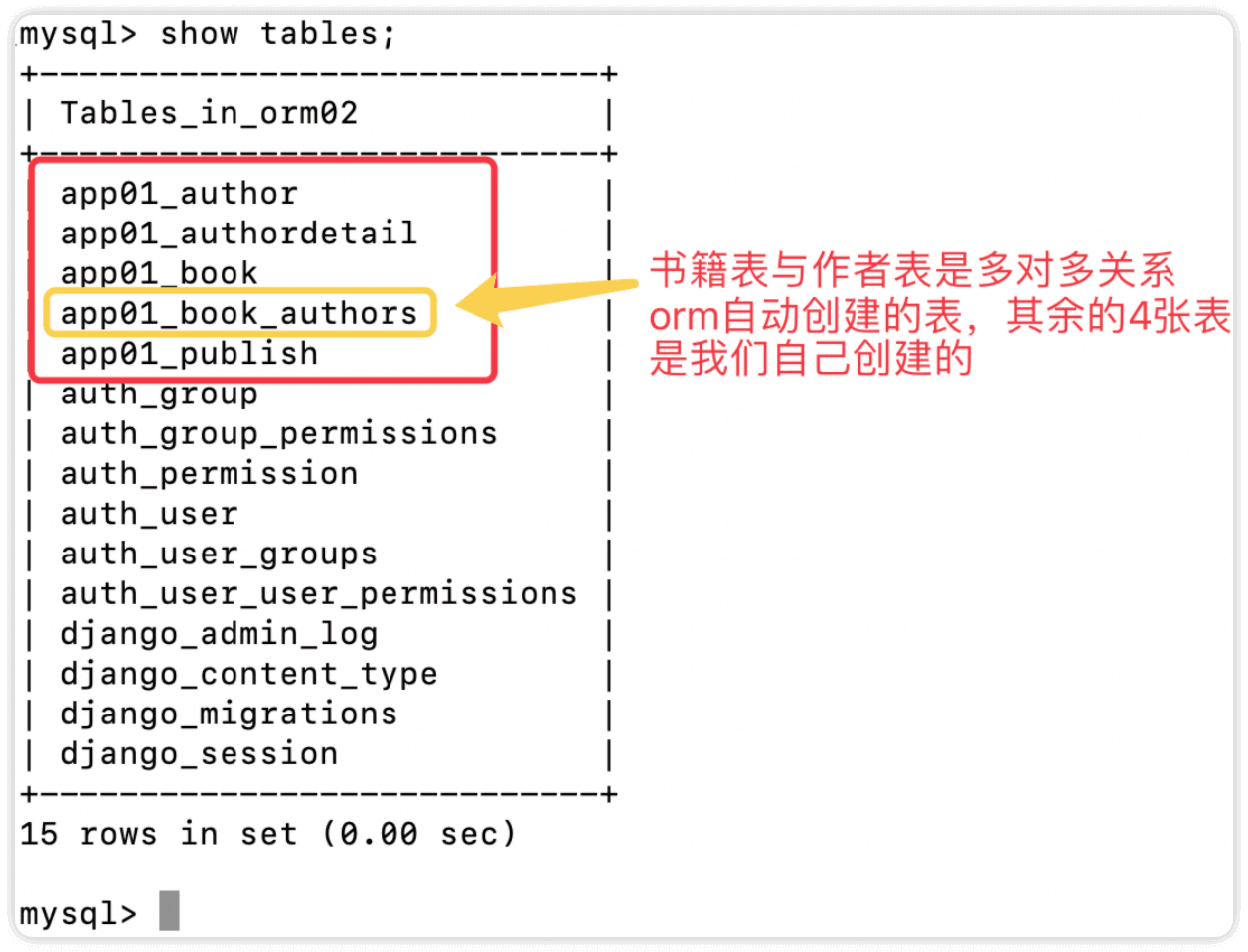
同步后的数据库,可以看到app01_book_authors这张表是orm自动帮我们创建的
5.2.3.1 增
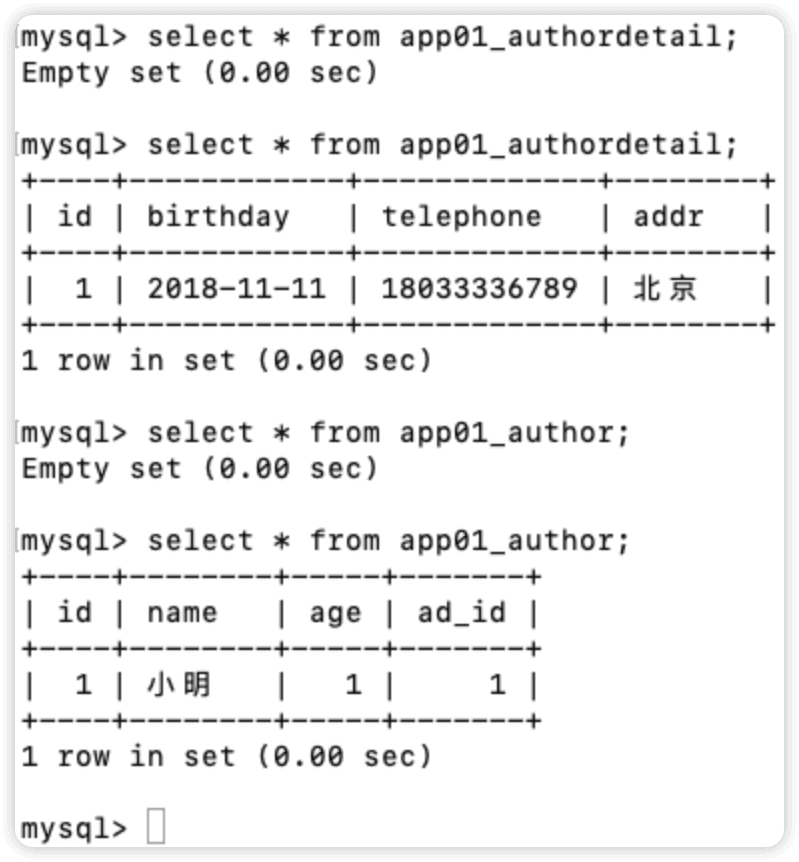
views文件
一对一,作者表和作者详细信息表
//给作者详细信息表添加一条记录
models.AuthorDetail.objects.create(
birthday='2018-11-11',
telephone='18033336789',
addr='北京'
)
//给作者表添加一条记录
models.Author.objects.create(
name='小明',
age=1,
#方式1
#关联作者详细信息表中id为1的
ad=models.AuthorDetail.objects.get(id=1)
#方式2(常用)
ad_id = 1
)
一对多,出版社和书籍表
models.Book.objects.create(
title='隔壁老王的故事',
publishDate='2011-01-01',
price='99',
#方式1
publishs=models.Publish.objects.get(id=1)
#方式2
publishs_id=2
)

多对多,书籍表和作者表
//方式一
book_obj = models.Book.objects.get(id=1)
author1 =models.Author.objects.get(id=1)
author2 =models.Author.objects.get(id=2)
#向关联书籍表和作者表的第3张表中插入作者1和作者2,书籍id为1的书的作者有2个,分别为作者id为1的和作者id为2的
#方式1
book_obj.authors.add(author1,author2)
#方式2
book_obj.authors.add(*[author1,author2])
//方式二
book_obj = models.Book.objects.get(id=1)
#方式1
book_obj.authors.add(1,2)
#方式2
book.obj.authors.add(*[1,2])
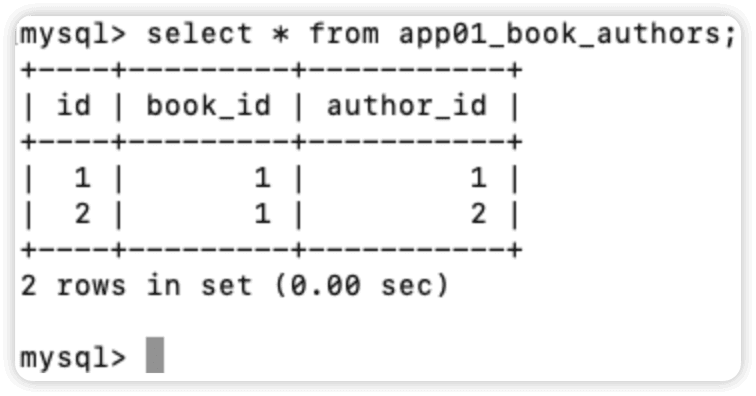
查看关联作者表和书籍表的第3张表app01_book_authors,书籍id为1的书作者有2个
5.2.3.2 删
一对一、一对多删除方式一样
models.Author.objects.get(id=1).delete()
删除了作者表中id为1的记录,但是不会影响作者详细信息表中作者id为1的记录
作者表的id作为外键关联作者详细信息表中的作者id,可以理解为我抱别人的大腿,删除我自己不影响别人,但是别人如果删除大腿会影响我
作者表是关联者,作者详细信息表是被关联者
多对多
//方式一 remove 移除
#找到书籍id为1的书
book_obj = models.Book.objects.get(id=1)
#删除书籍id为1的书的作者id为2和3
book_obj.authors.remove(2,3)
//方式二 clear 全部清空
#把书籍id为1的对应的作者全部删除
book_obj = models.Book.objects.get(id=1)
book_obj.authors.clear()
5.2.3.3 改
一对多和一对一和单表是一样的
#将书籍表中id为1的数据数名修改为python从入门到放弃并且出版社修改为出版社id为3的
book_obj = models.Book.objects.filter(id=1).update(
title='python从入门到放弃',
#方式1
publishs=models.Publish.objects.get(id=3)
#方式2
publishs_id=3
)
多对多
//set 先清空再追加,set中必须写字符串,删除多个在列表中填写多个数值
#把书籍id为1的作者全部改为2
book_obj = models.Book.objects.get(id=1)
book_obj.authors.set(['2',])
5.2.3.4 查
基于对象的跨表查询
一对一
作者表和作者详细信息表
//正向查询
#查询作者小明的住址
author_obj = models.Author.objects.get(name='小明')
# author_obj.ad直接拿到authordetail表中的那个记录对
print(author_obj.ad.addr)
//反向查询
#查询作者详细信息表中电话号以170开头的作者名字
authordetail_ojb = models.AuthorDetail.objects.filter(
telephone__startswith='170').first()
print(book_obj) #不加first打印结果 <QuerySet [<Book: Book object>]>
print(book_obj) #加first打印结果 Book object
#authordetail_ojb.author中的author是类名小写,直接定位到app01_author这张表
print(authordetail_ojb.author.name)
关于正向查询和反向查询的说明
一对多
出版社表和书籍表
//正向查询
#查询python从入门到放弃这本书的出版社
book_obj = models.Book.objects.filter(title='python从入门到放弃').first()
print(book_obj.publishs.name)
//反向查询
pub_obj = models.Publish.objects.get(name='南京出版社')
#pub_obj.book_set.all()中book_set是结果可能为多个,最后的all是拿到的书籍对象所有信息
books = pub_obj.book_set.all().values('title')
print(books)
#查询南京出版社中数名包含linux的书
books = pub_obj.book_set.filter(title__contains='linux').values('title')
多对多
书籍表和作者表
//正向查询
#查询书籍表中书名为linux从入门到放弃的作者
book_obj = models.Book.objects.filter(title='linux从入门到放弃').first()
authors = book_obj.authors.all().values('name')
print(authors)
//反向查询 反向查询中用字段存在的表的小写类名,这里为book
#查询作者小明写的书
xiaoming_obj = models.Author.objects.get(name='小明')
ret = xiaoming_obj.book_set.all().values('title')
print(ret)
查询书籍表中书名为linux从入门到放弃的作者
基于双下划线的跨表查询 就是join连表查询
一对一
作者表与作者详细信息表
//查询作者小明的住址
#基于对象的跨表查询写法 正向查询
author_obj = models.Author.objects.get(name='小明')
#author_obj.ad直接拿到authordetail表中的那个记录对
print(author_obj.ad.addr)
#基于双下划线的跨表查询写法
#正向查询
ret = models.Author.objects.filter(name='小明').values('ad__addr')
print(ret)
#反向查询
ret = models.AuthorDetail.objects.filter(author__name='小明').values('addr')
print(ret)
正向查询中 关联字段__字段 就获得了关联表的数据
反向查询中 表名__字段
一对多
书籍表和出版社表
//查询东京出版社出版的书
#原生sql语句
select app01_book.title from app01_publish inner join app01_book on app01_publish.id = app01_book.publishs_id where app01_publish.name='东京出版社';
#正向查询
ret = models.Book.objects.filter(publishs__name='东京出版社').values('title')
#反向查询
ret = models.Publish.objects.filter(name='东京出版社').values('book__title')
多对多
书籍表和作者表
关联字段在书籍表中,从书籍表查询是正向查询
#查询一下小明写了哪些书
#正向查询 关联字段在book表中,现在要查询小明写了哪些书,当前是book表,表中没有作者名字的字段,因此需要先连表然后在取值
ret = models.Book.objects.filter(authors__name='小明').values('title')
print(ret)
#反向查询 现在要查询小明写了哪些书,当前是author表,表中有作者名字的字段,因此不需要先连表,已知字段在本表的就可以先写条件最后在连表
ret = models.Author.objects.filter(name='小明').values('book__title')
print(ret)
关联的方式,正向查询和反向查询都可以使用,关键在于查询的条件
关联字段__字段 就获得了关联表的数据
小写类名__字段
聚合查询
aggregate聚合查询,结果是普通字典,queryset的结束符
#导入相关模块
from django.db.models import Avg,Max,Min,Count,Sum
//查询书籍表中价格最高的
obj = models.Book.objects.all().aggregate(a=Max('price'))
print(obj)
结果:
{'a': Decimal('125.00')}
分组查询
//查询每个出版社出版的书的最高价格
#方式一
ret = models.Book.objects.values('publishs_id').annotate(m=Max('price'))
print(ret)
结果:
<QuerySet [{'publishs_id': 2, 'm': Decimal('125.00')}, {'publishs_id': 3, 'm': Decimal('99.00')}]>
方式一写法说明
values写在annotate前面,意思是以values括号内的字段作为分组的依据,annotate里面是你要做的统计结果,这样,返回结果为queryset类型数据,里面是字典{'publishs_id':1,'m':100}
#方式二
#从出版社表中查询,需要连接book表,因为book表中才有书名和价格,这么写表示直接以publish这张表的id进行分组
ret = models.Publish.objects.annotate(m=Max('book__price')).values('m','name')
print(ret)
结果:
<QuerySet [{'name': '东京出版社', 'm': Decimal('99.00')}, {'name': '南京出版社', 'm': Decimal('125.00')}, {'name': '北京出版社', 'm': None}]>
方式二写法说明
annotate直接写在了objects后面,意思是按照前面表的所有的数据(默认是id值)作为分组依据,结果返回的是前面这个表的所有models对象(model对象中包含了每个对象自己的统计结果),在通过values来取值,取值时可以直接写字段和统计结果的别名,也是queryset类型,里面是字典{'m':100,'name':'东京出版社'}
F和Q查询
在book表中添加连个字段:点赞(dianzan)和评论(pinglun)
class Book(models.Model):
title = models.CharField(max_length=32)
publishDate=models.DateField()
dianzan = models.IntegerField(default=100)
pinglun = models.IntegerField(default=100)
price=models.DecimalField(max_digits=5,decimal_places=2)
publishs=models.ForeignKey(to="Publish",to_field="id",on_delete=models.CASCADE)
app01_book表中内容
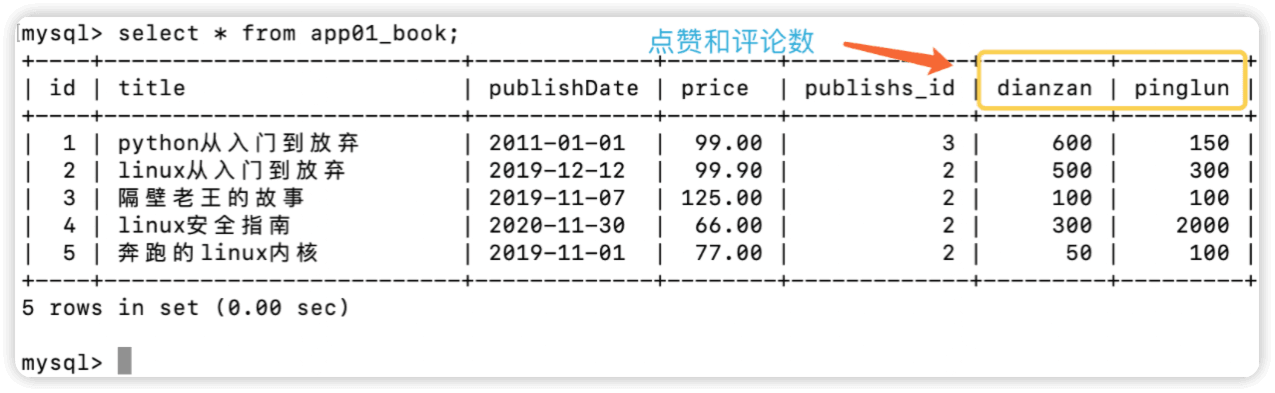
F查询 F查询用于一张表中的两个字段比较之后的符合条件的结果集
//查询book表中点赞数大于评论数的所有书籍
#low版写法
list1 = []
books = models.Book.objects.all()
for i in books:
if i.dianzan > i.comment:
list1.append(i)
#F查询写法
ret = models.Book.objects.filter(dianzan__gt=F('pinglun')).values('title')
print(ret)
结果:
<QuerySet [{'title': 'python从入门到放弃'}, {'title': 'linux从入门到放弃'}]>
//F还支持四则运算,例如将book表中的价格都上调50元models.Book.objects.all().update(
price=F('price')+50
)
Q查询 Q查询用于多个条件有与、或、非时的综合查询
与:& 或:| 非:~
orm执行原生sql语句
//方式一
ret = models.Book.objects.raw/branch('select * from app01_book')
for i in ret:
print(i.title)
结果:
会把表中所有书名打印出来
//方式二 django自带的连接通道(在项目下同名目录__init__.py中配置的pymysql)
from django.db import connection
import pymysql
def query(request):
conn = pymysql.connect()
cursor = connection.cursor()
cursor.execute('select * from app01_book;')
print(cursor.fetchall())
//方式三
def query(request):
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='PAPAlichencan!1',
database='orm02',
charset='utf8'
)
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute('select * from app01_book;')
print(cursor.fetchall())
结果:
[{'id': 1, 'title': 'python从入门到放弃', 'publishDate': datetime.date(2011, 1, 1), 'price': Decimal('99.00'), 'publishs_id': 3, 'dianzan': 600, 'pinglun': 150}, {'id': 2, 'title': 'linux从入门到放弃', 'publishDate': datetime.date(2019, 12, 12), 'price': Decimal('99.90'), 'publishs_id': 2, 'dianzan': 500, 'pinglun': 300}, {'id': 3, 'title': '隔壁老王的故事', 'publishDate': datetime.date(2019, 11, 7), 'price': Decimal('125.00'), 'publishs_id': 2, 'dianzan': 100, 'pinglun': 100}, {'id': 4, 'title': 'linux安全指南', 'publishDate': datetime.date(2020, 11, 30), 'price': Decimal('66.00'), 'publishs_id': 2, 'dianzan': 300, 'pinglun': 2000}, {'id': 5, 'title': '奔跑的linux内核', 'publishDate': datetime.date(2019, 11, 1), 'price': Decimal('77.00'), 'publishs_id': 2, 'dianzan': 50, 'pinglun': 100}]
django外部脚本调用models数据库操作
使用场景:有的时候我们不想运行django项目只想执行一些视图中的逻辑,这个时候就用到了django外部脚本调用models数据库操作
操作方法:在django项目下新建一个xx.py文件,在xx.py文件中写入以下内容,然后直接运行这个xx.py文件就可以在不启动django项目的情况下而单独执行我们想执行的测试逻辑
#导入os模块
import os
if __name__ == '__main__':
#最后一个参数要写项目名.settings
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "orm02.settings")
#导入django
import django
django.setup()
#导入应用程序的models
from app01 import models
ret = models.Book.objects.all().values('title')
print(ret)
ORM事务和锁
锁
models.Book.objects.select_for_update().filter(id=1)
事务
//方式1 全局配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'mxshop',
'HOST': '127.0.0.1',
'PORT': '3306',
'USER': 'root',
'PASSWORD': '123',
"ATOMIC_REQUESTS": True, #全局开启事务,绑定的是http请求响应整个过程当中的sql
}
}
方式1中,django项目中所有的视图逻辑全部加上了事物
//方式2: 视图函数加装饰器
from django.db import transaction
@transaction.atomic
def viewfunc(request):
# This code executes inside a transaction.
逻辑语句
方式2中,我们只想给某一个视图函数加事物��,这个时候就用到了上述的方法
方式3: 上下文加装饰器
from django.db import transaction
def viewfunc(request):
# This code executes in autocommit mode (Django's default).
逻辑语句1
with transaction.atomic(): #保存点
# This code executes inside a transaction.
逻辑语句2
逻辑语句3
方式3中,我们只想给逻辑语句2添加事物,而其他语句不需要,这个时候就在逻辑语句2的上边写如上语句即可