OpenCode使用系列课程连载(3)——性能优化与故障排查篇
Excerpt
前两篇讲了 OpenCode 的基础用法和进阶技巧,相信大家已经能熟练使用了。但实际开发中,你可能会遇到这些问题:API 调用次数太多费用超支、AI 响应慢让人等得着急、配置文件搞不清楚优先级、遇到错误不知道怎么排查。今天这篇,咱们来解决这些痛点,让你的 AI 助手跑得更快、更稳、更省钱。目录一、性能优化:让 AI 跑得更快二、故障排查:遇到问题怎么办三、进阶配置:深度定制环境四、最佳实践和避坑指
前两篇讲了 OpenCode 的基础用法和进阶技巧,相信大家已经能熟练使用了。但实际开发中,你可能会遇到这些问题:API 调用次数太多费用超支、AI 响应慢让人等得着急、配置文件搞不清楚优先级、遇到错误不知道怎么排查。
今天这篇,咱们来解决这些痛点,让你的 AI 助手跑得更快、更稳、更省钱。
目录
一、性能优化:让 AI 跑得更快
二、故障排查:遇到问题怎么办
三、进阶配置:深度定制环境
四、最佳实践和避坑指南
五、实战案例:从瓶颈到优化
六、总结
一、性能优化:让 AI 跑得更快
1.1 减少 API 调用次数的实战技巧
API 调用次数直接关系到成本和速度。掌握这些技巧,能大幅减少不必要的调用。
会话复用
不要每次都重新解释项目背景:
# 完成一个功能模块后,下次继续开发
opencode --continue
这样 AI 还记得之前的上下文,不用重新解释。
批量处理
把多个相关任务合并为一个请求:
错误做法:
生成用户注册接口
生成用户登录接口
生成用户信息查询接口
生成用户信息更新接口
正确做法:
生成用户模块的所有 CRUD 接口,包括注册、登录、查询、更新
实战案例
开发一个包含 20 个 API 接口的后端服务:
| 优化策略 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| API 调用次数 | 200 次 | 50 次 | 降 75% |
| 开发时间 | 3 天 | 1.5 天 | 快 50% |
| 成本 | $50 | $15 | 省 70% |
具体做法:
-
20 个接口分成 4 个功能模块
-
每个模块一次请求完成
-
使用
opencode --continue恢复会话 -
正确的代码直接引用,不重复生成
1.2 模型选择优化策略
不同模型适合不同场景,选对模��型能让效率翻倍、成本减半。
快速响应场景
适用:简单查询、代码生成
推荐:DeepSeek-V3、Qwen-2.5-32B、Kimi
原因:响应快、成本低,简单任务用顶配模型提升不明显
高质量输出场景
适用:复杂功能开发、代码审查、架构设计
推荐:DeepSeek-R1、Kimi-Max
原因:理解能力强,生成代码质量高
成本敏感场景
适用:批量生成代码、文档生成
推荐:Qwen-2.5-72B
原因:性价比最高,质量接近顶配但成本低
离线场景
适用:无网络或敏感数据开发
推荐:本地部署 Qwen-2.5-7B、DeepSeek-Coder-V2-Lite
原因:数据不出本地,安全性高
模型选择决策
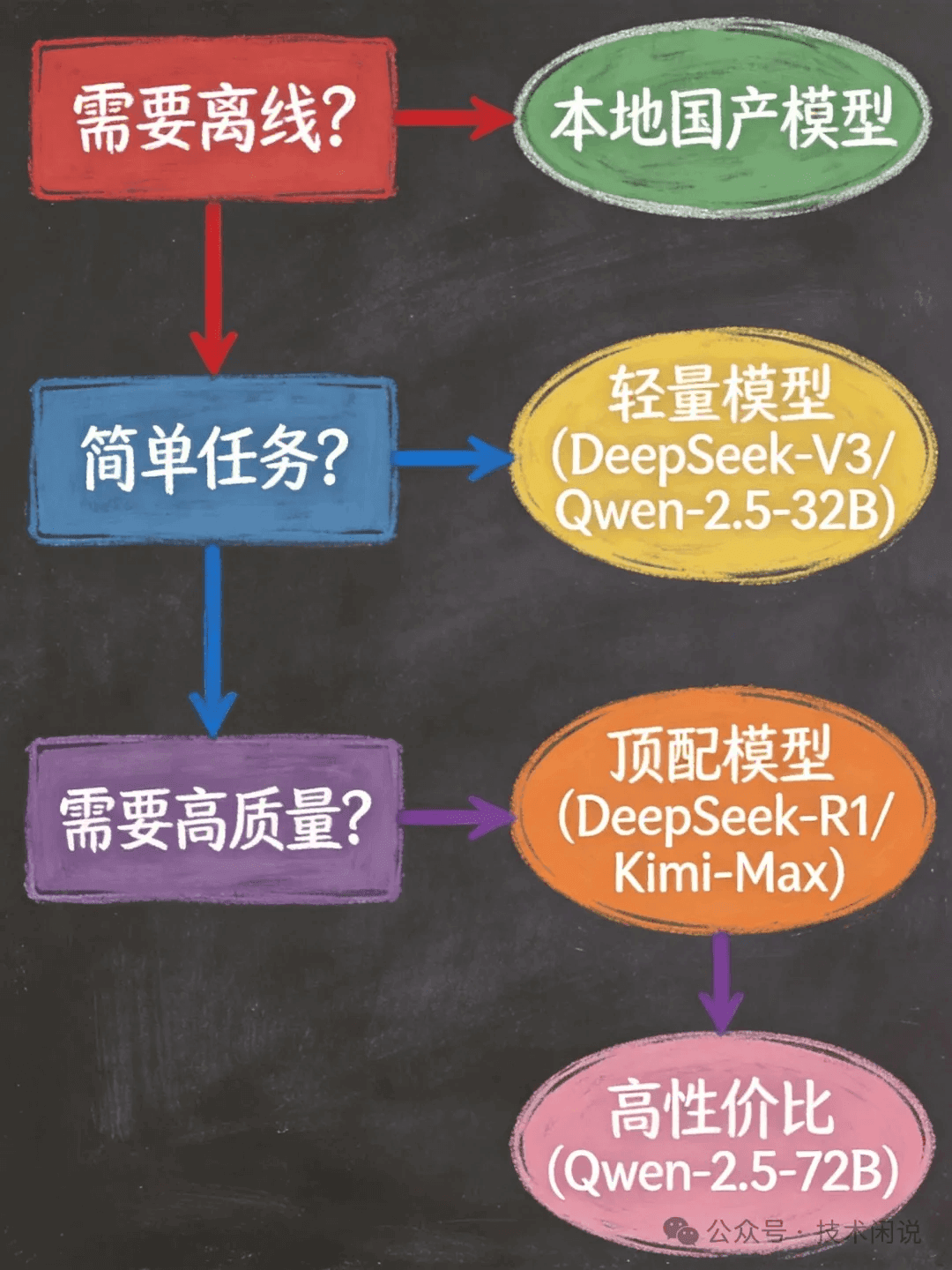
模型决策流程
1.3 提示词优化技巧
好的提示词能让 AI 更快理解需求,减少来回确认。
精简指令
错误:啰嗦不清
你好,我现在需要你帮我写一个用户登录接口,这个接口应该包含邮箱和密码两个字段...
正确:简洁明了
写一个用户登录接口,包含邮箱和密码字段,验证成功返回 token
上下文复用
用 AGENTS.md 存储项目规范,不在每次请求中重复。
AGENTS.md 示例:
# 项目规范
## 技术栈
- 框架:Gin
- 数据库:PostgreSQL
- 错误处理:明确错误码
避免冗余
错误:粘贴长代码
请优化这段代码:[粘贴200行代码]
正确:引用文件
请优化 @ main.go 中的代码
结构化指令
错误:指令不清晰
生成用户注册登录和查询接口
正确:结构化
生成用户模块的接口,包括:
1. 用户注册:邮箱、密码、验证码
2. 用户登录:邮箱、密码,返回 token
3. 用户信息查询:根据 user_id 查询
1.4 并发与批处理
大型项目用并发和批处理能大幅提升效率。
批处理技巧
错误:逐个生成
生成 User 模型的 CRUD 代码
生成 Order 模型的 CRUD 代码
生成 Product 模型的 CRUD 代码
正确:批处理
为 User、Order、Product 三个模型生成完整的 CRUD 代码
实战案例
微服务电商系统:
优化前(5 天):用户→订单→商品→支付→库存,逐个服务开发
优化后(3 天):
-
Day 1:用户服务和订单服务(20 个接口)
-
Day 2:商品服务和支付服务(16 个接口)
-
Day 3:库存服务和消息队列
效果:时间缩 40%,成本降 45%
二、故障排查:遇到问题怎么办
2.1 API 调用失败
API 调用失败是最常见的问题。
常见问题
| 问题类型 | 可能原因 | 解决方案 |
|---|---|---|
| 连接超时 | 网络问题、服务宕机 | 检查网络、切换模型 |
| 认证失败 | API 密钥错误、过期 | 检查凭证、更新密钥 |
| 速率限制 | 请求频率过高 | 降低频率、切换模型 |
| 模型不可用 | 模型维护、下线 | 切换备用模型 |
排查流程
步骤1:检查网络连接
ping api.deepseek.com
步骤2:检查 API 凭证
opencode config show
步骤3:查看错误日志
tail -f ~/.opencode/logs/opencode.log
步骤4:切换备用模型
opencode --model qwen2.5-72b
2.2 模型响应异常
现象1:重复输出
原因:提示词模糊
解决:明确指令结构
生成用户模块的接口,包括:
1. 用户注册:POST /api/user/register
2. 用户登录:POST /api/user/login
3. 用户信息查询:GET /api/user/:id
每个接口包含请求参数、响应格式、错误处理
现象2:格式错误
原因:模型理解偏差
解决方法:
-
重新提示明确格式要求
-
让 AI 自动检查修复
-
分步骤生成
现象3:内容不符合预期
原因:上下文不充分
解决:提供详细上下文或明确需求细节
2.3 工作区管理
工作区可以管理多个相关项目,共享配置和上下文。
工作区 vs 项目
| 对比维度 | 项目 | 工作区 |
|---|---|---|
| 范围 | 单个项目 | 多个相关项目 |
| 配置 | 项目级别 | 工作区级别 |
| 上下文 | 独立 | 共享 |
启用工作区
export OPENCODE_EXPERIMENTAL_WORKSPACES=1
echo 'export OPENCODE_EXPERIMENTAL_WORKSPACES=1' >> ~/.zshrc
source ~/.zshrc
创建和切换
# 创建工作区
opencode workspace create my-workspace
# 添加项目
opencode workspace add-project ~/project-a
opencode workspace add-project ~/project-b
# 切换工作区
opencode workspace switch my-workspace
实战场景
微服务架构:用户、订单、商品、支付服务,共享技术栈和配置
Monorepo:前端、后端、共享库,方便切换
多团队协作:共享项目规范和配置
2.4 常见错误码
| 错误码 | 含义 | 常见原因 | 解决方案 |
|---|---|---|---|
| 401 | 未授权 | API 密钥错误 | 检查密钥 |
| 403 | 禁止访问 | 密钥权限不足 | 检查权限 |
| 429 | 请求过多 | 频率超限 | 降低频率 |
| 500 | 服务器错误 | 服务内部错误 | 稍后重试 |
| 503 | 服务不可用 | 维护或过载 | 等待恢复 |
三、进阶配置:深度定制环境
3.1 配置文件优先级
OpenCode 支持多层级配置,不同位置的配置文件有不同优先级。
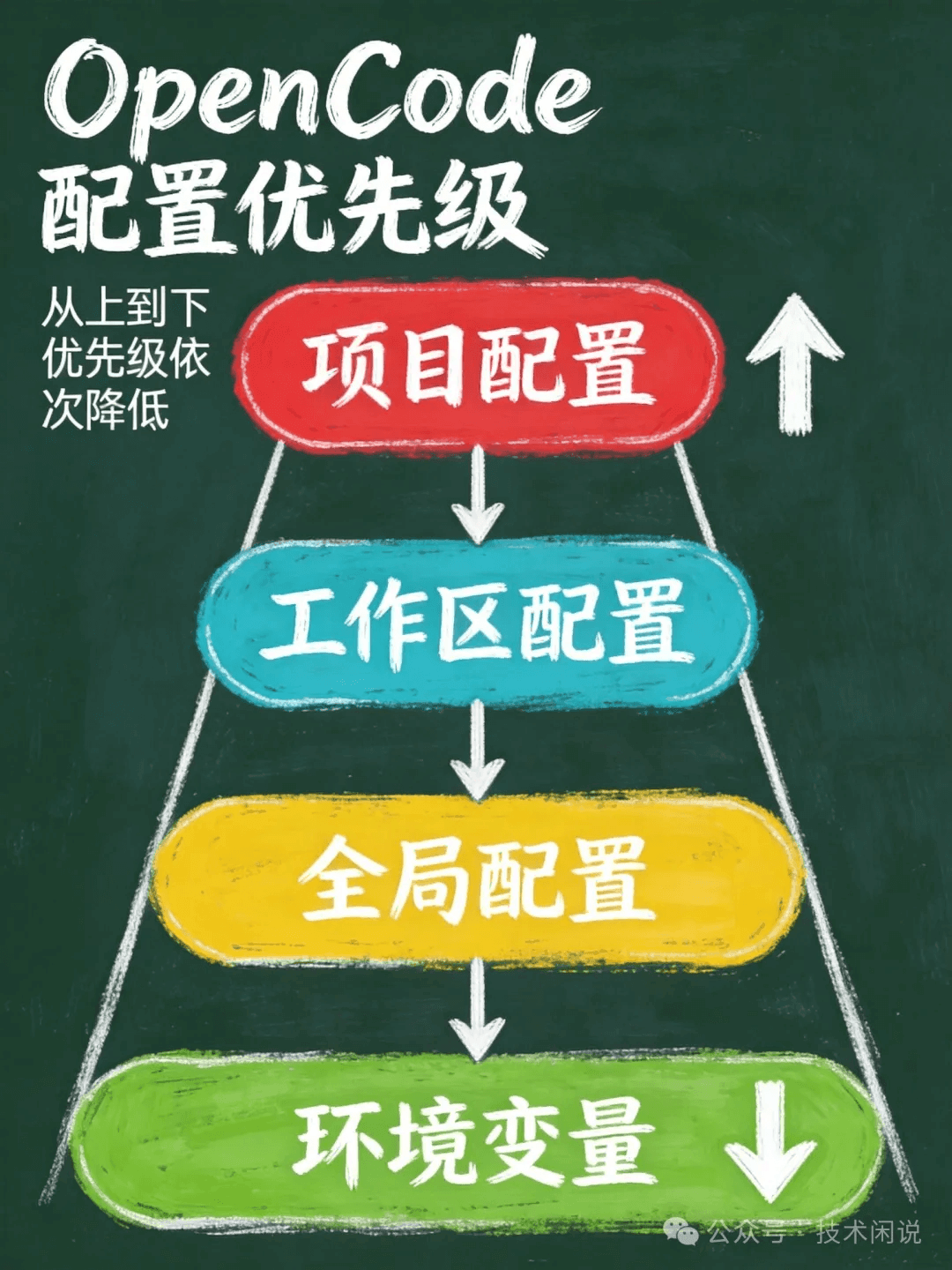
配置文件优先级
| 优先级 | 位置 | 配置文件 | 适用范围 |
|---|---|---|---|
| 1(最高) | 项目目录 | .opencode.json | 当前项目 |
| 2 | 工作区目录 | opencode.json | 工作区内所有项目 |
| 3 | 全局 | ~/.config/opencode/opencode.json | 所有项目 |
| 4(最低) | 环境变量 | 系统环境变量 | 默认值 |
优先级规则
-
高优先级覆盖低优先级
-
不同配置项可叠加
-
项目配置优先级最高
3.2 全局配置文件
配置文件位置
| 系统 | 位置 |
|---|---|
| Windows | C:\Users\你的用户名\.config\opencode\opencode.json |
| Linux/Mac | ~/.config/opencode/opencode.json |
配置示例
前两篇讲了 OpenCode 的基础用法和进阶技巧,相信大家已经能熟练使用了。但实际开发中,你可能会遇到这些问题:API 调用次数太多费用超支、AI 响应慢让人等得着急、配置文件搞不清楚优先级、遇到错误不知道怎么排查。{
"$schema": "https://opencode.ai/config.json",
// === 模型 ===
"model": "deepseek/deepseek-r1",
"small_model": "deepseek/deepseek-v3",
"default_agent": "build",
// === Provider ===
"provider": {
"deepseek": {
"options": {
"apiKey": "{env:DEEPSEEK_API_KEY}",
"timeout": 600000
}
}
},
// === 界面 ===
"theme": "dark",
"tui": {
"scroll_speed": 3,
"diff_style": "auto"
},
"keybinds": {
"leader": "ctrl+x",
"session_new": "<leader>n"
},
// === 服务器 ===
"server": {
"port": 4096,
"hostname": "localhost"
},
// === 行为 ===
"share": "manual",
"compaction": {
"auto": true,
"prune": true
},
"watcher": {
"ignore": ["node_modules/**", "dist/**"]
},
// === 权限 ===
"permission": {
"edit": "ask",
"bash": {
"*": "ask",
"git *": "allow"
}
}
}
核心配置项
-
default_model:默认模型 -
timeout:请求超时时间(秒) -
retry_times:重试次数 -
max_tokens:最大 tokens 数 -
temperature:输出随机性(0-1)
3.3 项目级和工作区级配置
项目级配置
位置:~/your-project/.opencode.json
项目级配置仅覆盖必要的配置项,保持简洁:
{
"model": "deepseek/deepseek-v3",
"theme": "light"
}
工作区级配置
位置:~/.opencode/workspaces/my-workspace/opencode.json
工作区内所有项目共享此配置:
{
"model": "deepseek/deepseek-r1",
"provider": {
"deepseek": {
"options": {
"apiKey": "{env:DEEPSEEK_API_KEY}"
}
}
},
"permission": {
"edit": "ask",
"bash": {
"*": "ask",
"git *": "allow"
}
}
}
3.4 启用网络搜索功能
什么是网络搜索
让 AI 能自动搜索最新信息,回答时效性问题。
启用方法
# macOS / Linux
export OPENCODE_ENABLE_EXA=true
echo 'export OPENCODE_ENABLE_EXA=true' >> ~/.zshrc
source ~/.zshrc
使用场景
-
查询最新技术文档
-
搜索错误解决方案
-
了解库的最新版本
实战示例
查询 FastAPI 的最新版本和主要特性
AI 会自动搜索并回答最新信息。
四、最佳实践和避坑指南
4.1 成本控制
设置预算预警
每周检查一次成本统计:
opencode stats
模型降级策略
-
开发阶段:轻量模型(DeepSeek-V3)
-
代码审查:高性价比模型(Qwen-2.5-72B)
-
最终审查:顶配模型(DeepSeek-R1)
4.2 稳定性保障
备用模型
| 主要模型 | 备用模型 |
|---|---|
| DeepSeek-R1 | Qwen-2.5-72B |
| Kimi-Max | DeepSeek-R1 |
| DeepSeek-V3 | Qwen-2.5-32B |
错误自动重试
{
"model": {
"retry_times": 3,
"retry_delay": 5
}
}
4.3 性能监控
| 指标 | 正常范围 |
|---|---|
| 平均响应时间 | < 30秒 |
| 错误率 | < 5% |
| 会话恢复成功率 | > 95% |
4.4 配置管理
分层配置
-
全局:通用设置
-
工作区:共享设置
-
项目:个性化设置
版本控制
# 项目配置提交到 Git
git add .opencode.json
git commit -m "Add project config"
# 全局配置不提交
echo ".config/opencode/" >> .gitignore
五、实战案例:从瓶颈到优化
5.1 场景描述
开发一个包含 20 个 API 接口的后端服务,初期开发慢、成本高。
5.2 问题诊断
症状:
-
开发慢:每个接口 10-20 分钟
-
API 调用多:累计 200+ 次
-
成本高:单日 $50
-
重复工作多
根本原因:
-
每个接口单独请求 AI
-
全部用顶级模型
-
没有用会话管理
-
提示词冗长
5.3 优化方案
1. 批处理优化
优化前:20 个接口 × 4 次交互 = 80 次 AI 请求
优化后:20 个接口分成 4 个模块,总计 4 次请求(降 95%)
2. 模型优化
-
代码生成:DeepSeek-V3(快速便宜)
-
代码审查:Qwen-2.5-72B(性价比高)
-
最终审查:DeepSeek-R1(最佳质量)
3. 会话管理
# 完成模块后保存
exit
# 下次继续
opencode --continue
4. 提示词优化
创建 AGENTS.md 存储项目规范,直接引用文件。
5.4 优化效果
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| API 调用次数 | 200 次 | 50 次 | 降 75% |
| 成本 | $50 | $15 | 省 70% |
| 开发时间 | 3 天 | 1.5 天 | 快 50% |
| 响应时间 | 45 秒 | 20 秒 | 快 56% |

成本优化对比
5.5 关键经验
-
批处理是性能优化的关键
-
模型选择要合理,不是所有任务都需要顶配
-
会话管理很重要,善用�
--continue -
提示词要精简,用文件引用避免冗长
六、总结
这篇教程我们讲了三件事:
性能优化:减少 API 调用、合理选择国产大模型、优化提示词、使用批处理
故障排查:掌握错误码解决方案、处理模型响应异常、使用工作区管理项目
进阶配置:理解配置文件优先级、掌握全局/工作区/项目配置、启用网络搜索
为什么选择国产模型?
本系列课程中推荐使用 DeepSeek、Qwen 等国产大模型,原因很简单:
无需翻墙:国内服务直连,稳定可靠,不用担心网络问题
价格便宜:国产模型 API 调用成本远低于国外模型,性价比极高
中文友好:对中文的理解和生成能力更强,更符合国内开发场景
持续进化:国产模型迭代速度快,某些领域已不输国外顶配模型
OpenCode 是个强大的工具,掌握了这些技巧,你就能更高效地用它来提升开发效率。记住,工具的价值在于怎么用,不断实践和优化,才能让 AI 真正成为你的得力助手。