[toc]
grep命令
正则表达式
基本正则表达式
| 元字符 | 功能 | 示例 | 示例匹配对象 | 实际匹配示例 |
|---|---|---|---|---|
^ | 行首定位符 | ^love | 匹配所有以 love 开头的行 | love is in the air(匹配),I love coding(不匹配) |
$ | 行尾定位符 | love$ | 匹配所有以 love 结尾的行 | I love(匹配),I love coding(不匹配) |
* | 前边的字符连续出现0次或多次 | *love | love 前边有0个或多个连续出现的字符 | love(匹配),alove(匹配),aaalove(匹配),blove(不匹配) |
. | 匹配除换行外的多个字符 | l..e | 字母 l 和 e 之间有2个任意字符 | like(匹配),love(不匹配,因为 . 只匹配一个字符),lame(匹配) |
[] | 匹配中括号内的任意字符 | [lL]ove | 匹配 love 或 Love | love(匹配),Love(匹配),dove(不匹配) |
[^] | 匹配不在中括号内的任意字符 | [^a-km-z]ove | 匹配包含 ove ,但 ove 之前的那个字符不在 a 至 k 或 m 至 z 之间的字符 | Love(匹配),Move(匹配),Jove(不匹配),Kove(不匹配) |
\(\) | 分组,主要做反向引用 | (a)\1 | (a): 这个部分会捕获字符 a,并将其存储在第一个捕获组中。\1: 这是一个反向引用,指的是第一个捕获组中的内容。也就是说,\1 会匹配捕获组中已经匹配到的内容(在这里就是字符 a)因此,(a)\1 这个正则表达式会匹配两个连续的 a,即 aa | aa(匹配),a(不匹配),aaa(匹配前两个 a) |
& | 保存查找串以便在替换中引用 | s/love/& | & 代表查找串,将 love 替换为 love,也就是不对文本进行任何改变 | I love you 替换结果为 I love you(不变) |
\< | 词首定位符 | <love | 匹配以 love 开头的单词的行 | love is kind(匹配),belove(不匹配),Love story(匹配) |
\> | 词尾定位符 | love> | 匹配以 love 结尾的单词的行 | I truly love(匹配),lovely(不匹配),mylove(不匹配) |
x\{m\} | 连续 m 个 x | x{5} | 前边的 x 连续出现5次 | xxxxx(匹配),xxxx(不匹配),xxxxxx(匹配前5个) |
x\{m,\} | 至少 m 个 x | x{5,} | 前边的 x 连续出现至少5次 | xxxxx(匹配),xxxxxx(匹配),xxxx(不匹配) |
x\{m,n\} | 至少 m 个 x ,至多 n 个 x | x{3,5} | 前边的 x 最少出现3次,最多出现5次 | xxx(匹配),xxxx(匹配),xxxxx(匹配),xxxxxx(匹配前5个) |
扩展正则表达式
| 元字符 | 功能 | 示例 | 示例匹配对象 | 实际匹配示例 |
|---|---|---|---|---|
? | 前边的字符出现0词或1词 | m? | 匹配前边的 m 出现0次或1次 | map(匹配 m),ap(匹配,m 不出现),mmmmm(只匹配第一个 m) |
+ | 前边的字符连续出现1词或多次 | m+ | 匹配前边的 m 出现1次或多次 | m(匹配),mm(匹配),mmm(匹配),amap(匹配 m,忽略其他) |
| ` | ` | 或者 | `m | n` |
() | 分组,主要是向后引用 | (aaa)\1 | 引用前边的第一个分组,\1 表示引用 | aaaaaa(匹配前两个 aaa),aaabbb(不匹配),aaaaaaa(匹配前两个 aaa 和下一个 a) |
{m} | 前边的字符正好出现m次 | a{m} | 前边的字符 a 出现 m 次 | aaa(匹配),aa(不匹配),aaaa(匹配前3个 a) |
{m,} | 前边的字符最少出现 m 次 | a{m,} | 前边的字符 a 最少出现 m 次 | aa(匹配),aaaa(匹配),a(不匹配) |
{m,n} | 前边的字符最少出现 m 次,最多出现 n 次 | a{m,n} | 前边的字符 a 最少出现 m 次,最多出现 n 次 | aa(匹配),aaa(匹配),aaaa(匹配),aaaaa(匹配前4个 a) |
特殊字字符类
[:alnum:] [a-zA-Z0-9]匹配所有字母和数字字符
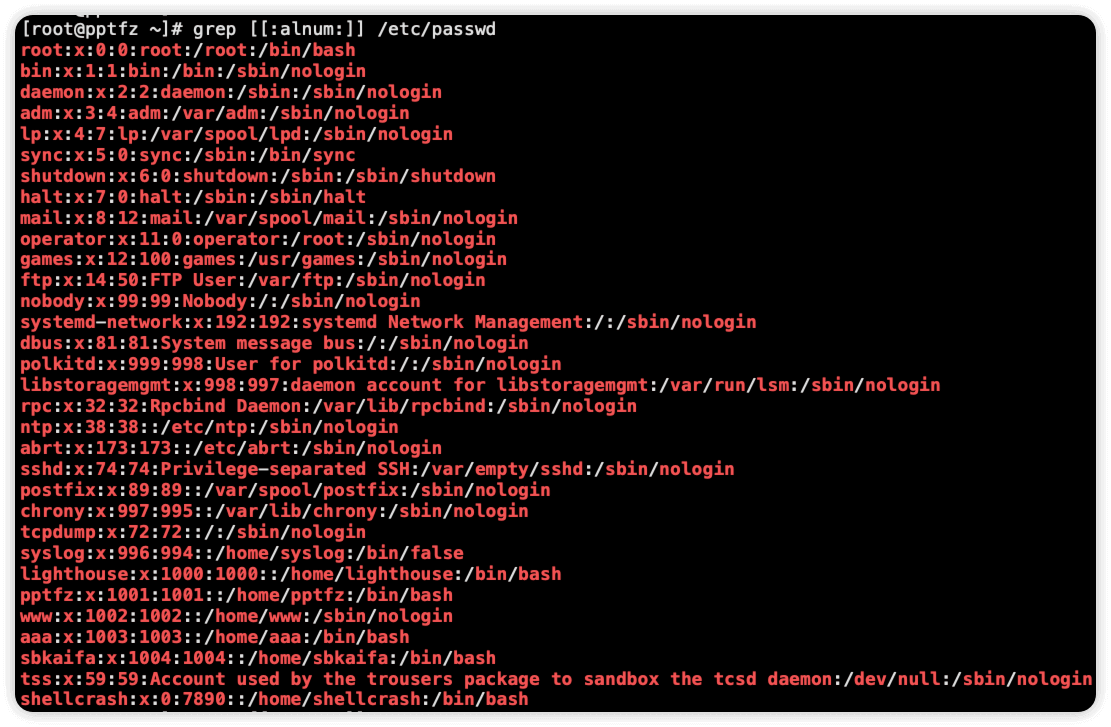
[:alpha:] 匹配任意一个字母(包括大小写)
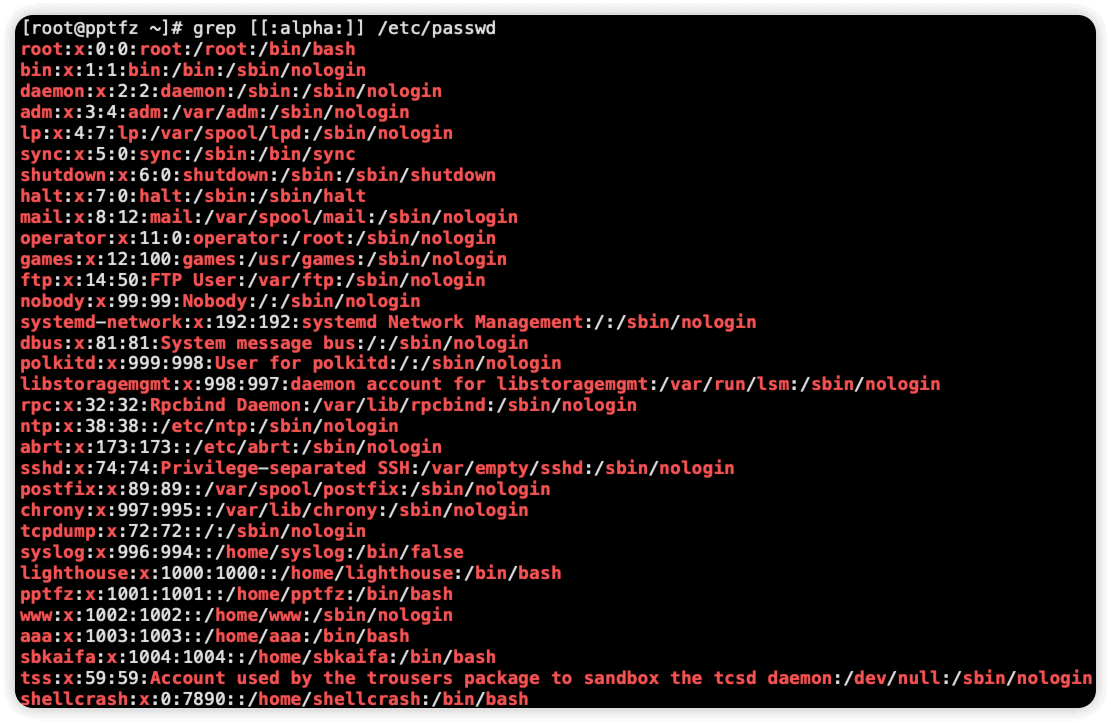
[:digit:] 匹配任意一个数字
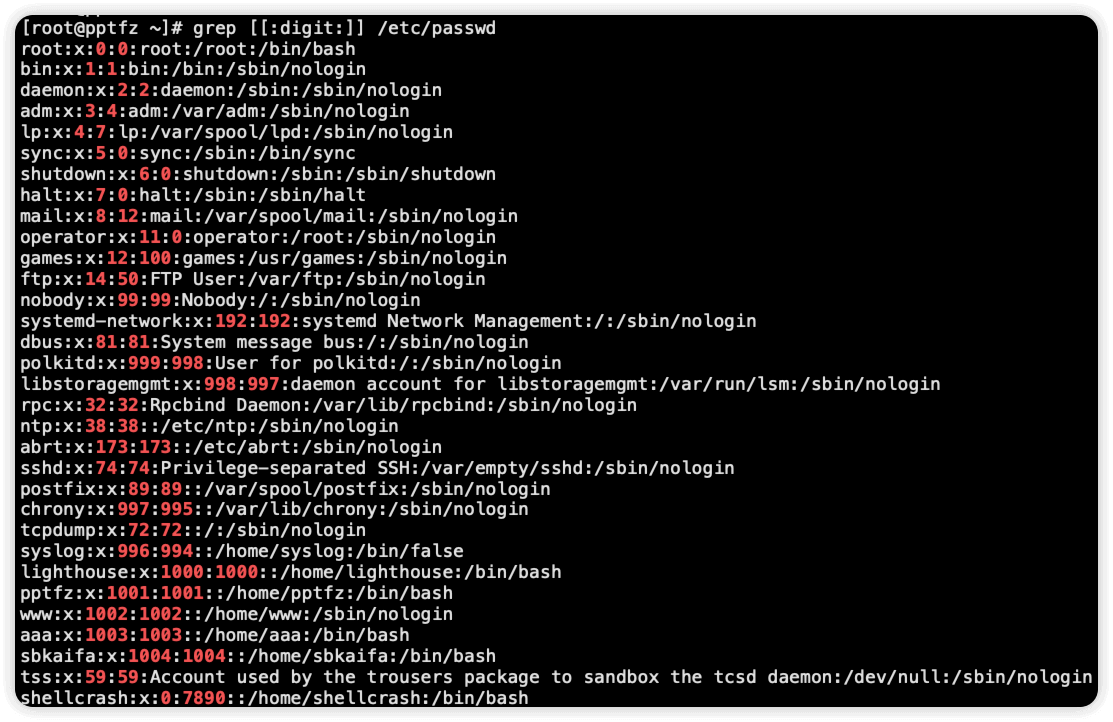
[:lower:] 匹配小写字母
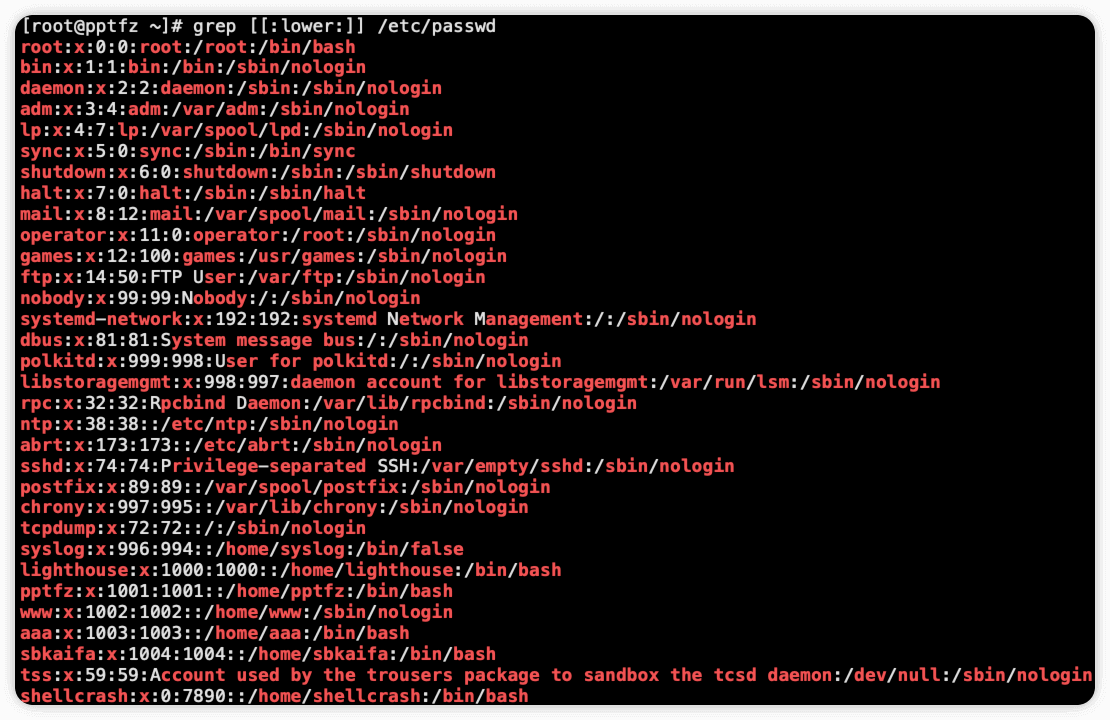
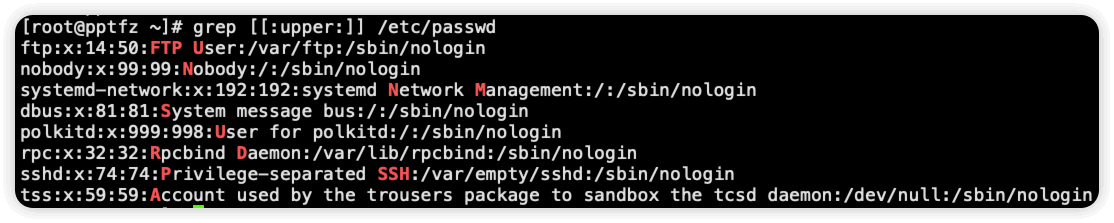
[:upper:] 匹配大写字母
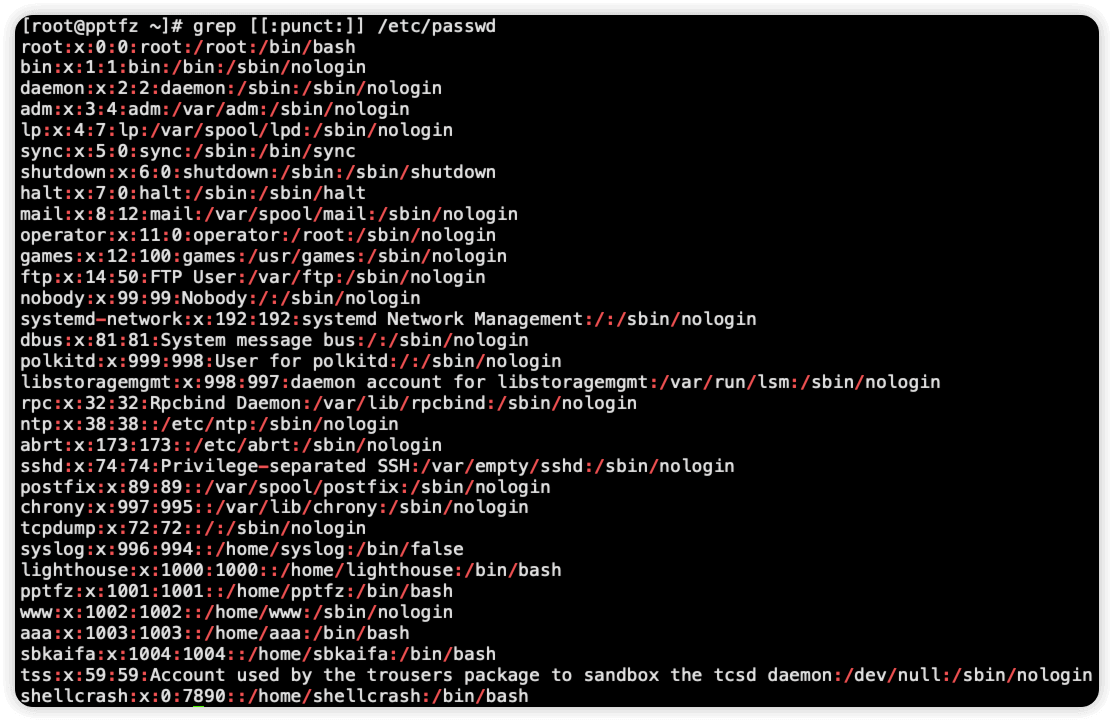
[:punct:] 匹配标点符号
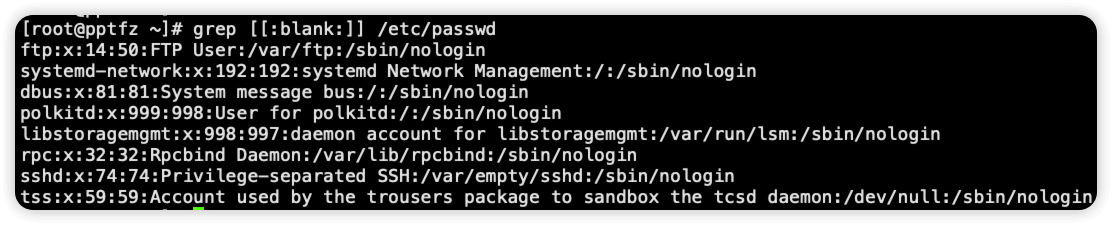
[:blank:] 匹配空格与制表符
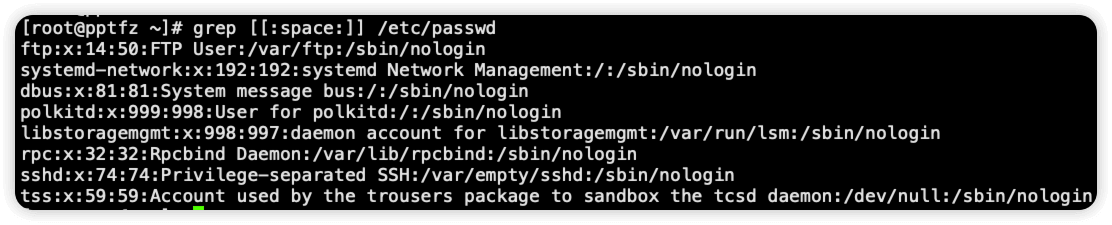
[:space:] 匹配一个包括换行符、回车等在内的所有空白字符
[:graph:] 匹配任意可看的见的且可打印的字符
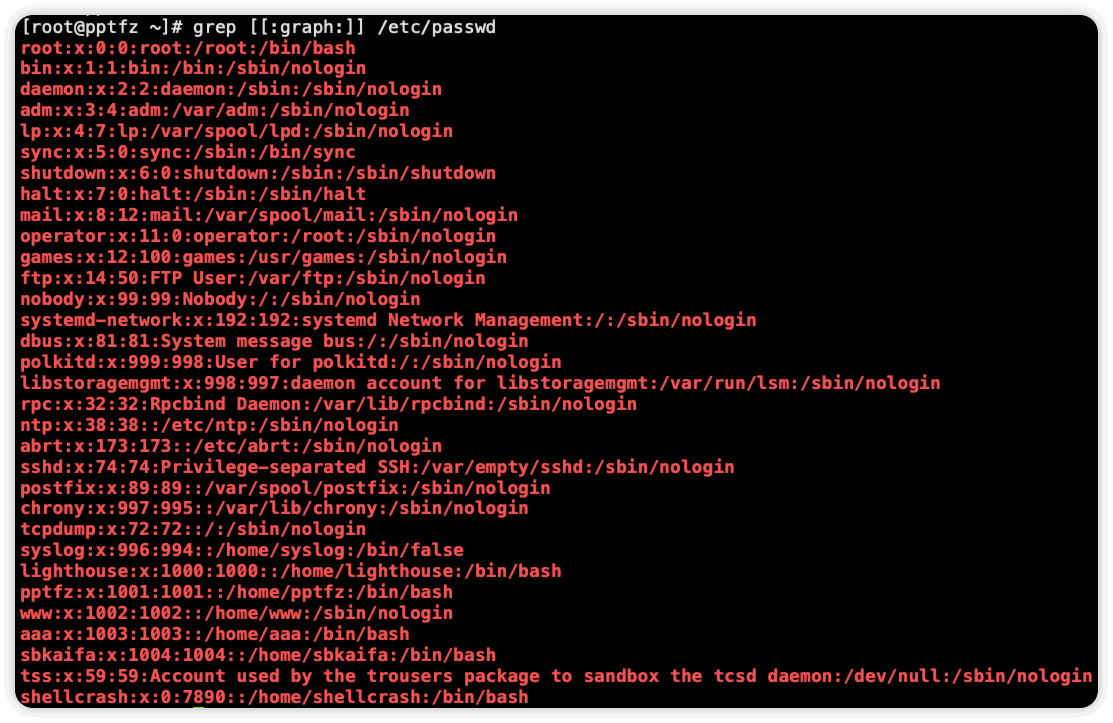
[:print:] 匹配任何一个可以打印的字符
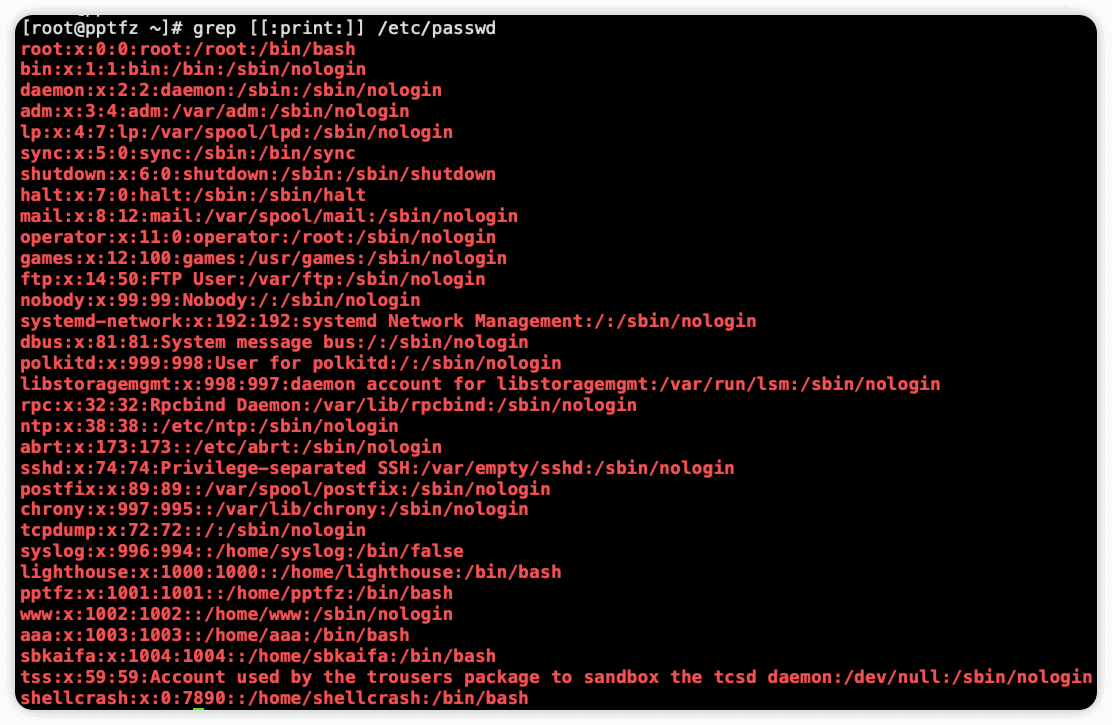
[:xdigit:] 匹配任意一个16进制数(0-9,a-f,A-F)
grep命令
命令说明
说明
grep是一个命令行实用程序,用于在纯文本数据集中搜索与 Regular expression 匹配的行,grep全称是 g/re/p (global / regular expression search / and print)
命令格式
grep [options] file
选项
创建示例文件
cat > test.txt << EOF
aaaAAA
!aaa!
aaabbbAAABBB
ababab
ab123aaaBBB
EOF
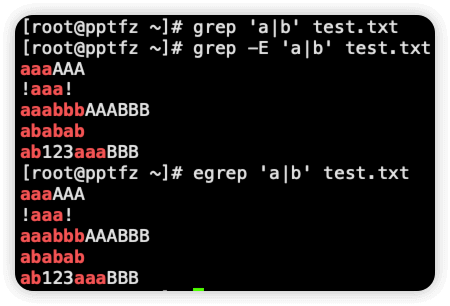
-E 如果加这个选项,那么后面的匹配模式就是扩展的正则表达式,也就是 grep -E = egrep
# 标准正则表达式过滤无结果
$ grep 'a|b' test.txt
# 加-E选项,效果就和egrep一样了
$ grep -E 'a|b' test.txt
aaaAAA
!aaa!
aaabbbAAABBB
ababab
ab123aaaBBB
$ egrep 'a|b' test.txt
aaaAAA
!aaa!
aaabbbAAABBB
ababab
ab123aaaBBB
-i 比较字符时忽略大小写区别
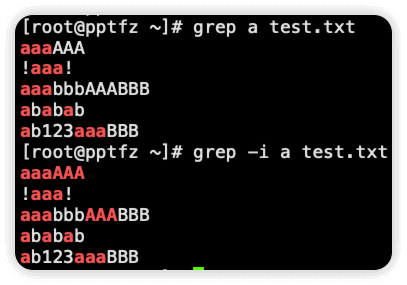
-l 过滤的时候只显示文件名
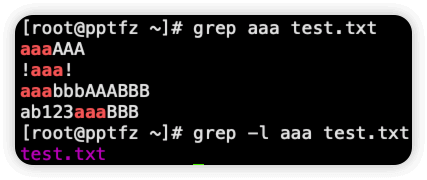
-w 把表达式作为词来查找,相当于正则中的 <...> (...表示你自定义的规则)
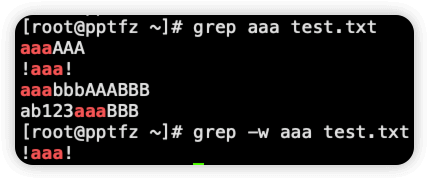
-x 被匹配到的内容,正好是整个��行,相当于正则 ^...$
修改示例文件
cat > test.txt << EOF
aaaAAA
!aaa!
aaabbbAAABBB
ababab
ab123aaaBBB
aaa
aaa789
EOF
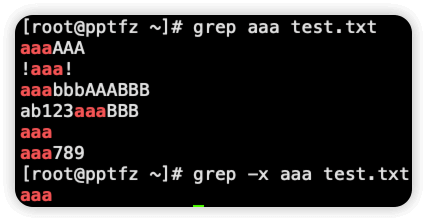
-v 取反
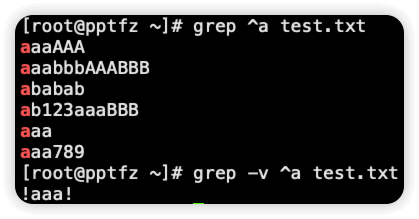
-c count,统计,统计匹配结果的行数,不是匹配结果的次数,是行数
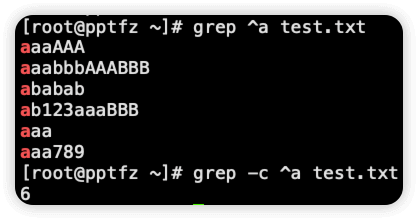
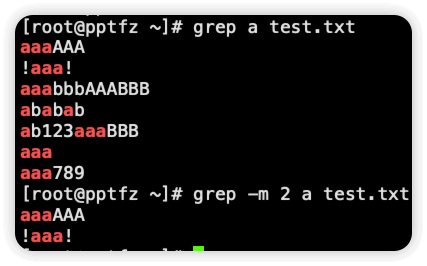
-m 只匹配规定的行数,之后的内容就不再匹配了
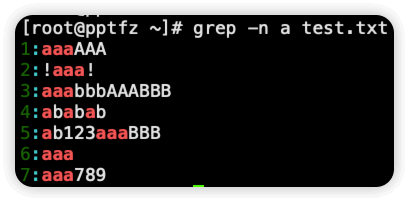
-n 在输出的结果里显示行号
说明
这里的行号是该行内容在原文件中的行号,而不是在输出结果中行号
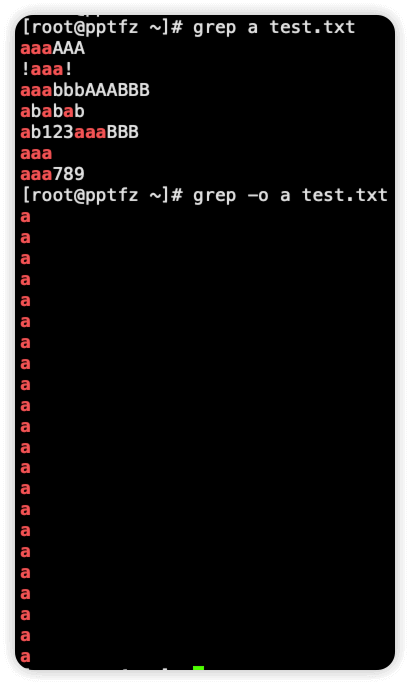
-o 只显示匹配内容
说明
grep 默认是显示满足匹配条件的一行,加上这个参数就只显示匹配结果,比如我们要匹配一个 ip 地址,就只需要结果,而不需要该行的内容
-R 递归匹配,如果要在一个目录中多个文件或目录匹配内容,则需要这个参数
-B 输出满足条件行的前几行
说明
比如 grep -B 3 "aa" file 表示在 file 中输出有 aa 的行,同时还要输出 aa 的前3行
-A 这个与 -B 类似,输出满足条件行的后几行
-C 这个相当于同时用 -B -A,也就是前后都输出
-P 支持perl正则
grep扩展用法
扩展用法1 grep后向引用
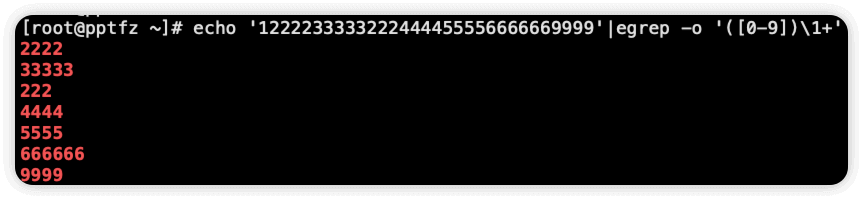
示例:将文本中连续相同的数字打印出来
说明
() 表示匹配的内容,当前为匹配数字, \1 为后向引用
命令后边如果写 + 就会无法截取1,因为1只有一个
echo '1222233333222444455556666669999'|egrep -o '([0-9])\1+'
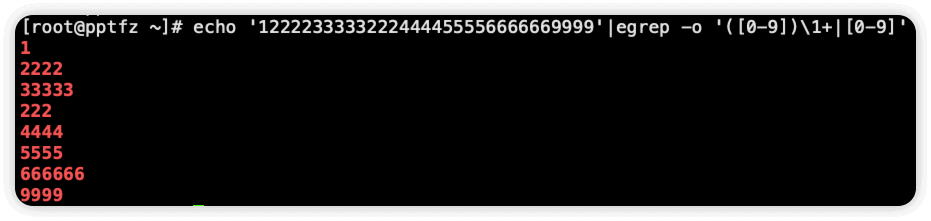
此时就需要在后边再单独匹配数字1
echo '1222233333222444455556666669999'|egrep -o '([0-9])\1+|[0-9]'
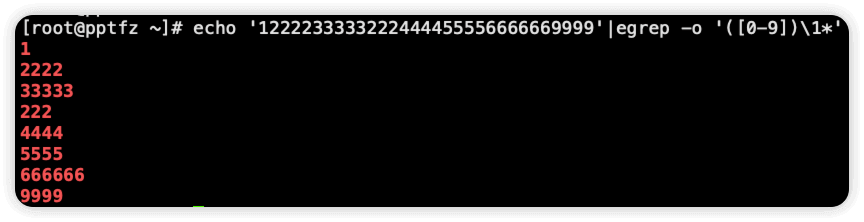
另外两种写法
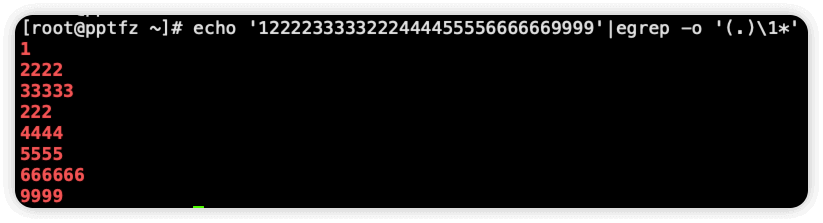
echo '1222233333222444455556666669999'|egrep -o '([0-9])\1*'
echo '1222233333222444455556666669999'|egrep -o '(.)\1*'
扩展用法2 grep -P 与零宽断言匹配
说明
零宽断言:perl语言正则匹配
核心:截取特定字符串左边或右边的内容
截取string右边的内容
lookahead (?=string)
截取string左边的内容
lookbehind (?<=string)
零宽断言截取字符串
示例1:取出文件中 : 右边的内容
创建示例文件
cat > test.txt << EOF
id:01 id:02 id:03 id:04 id:05 id:06 id:07 id:08 id:09 id:10 666 test666
EOF
截取出 : 右边的数字
命令解析
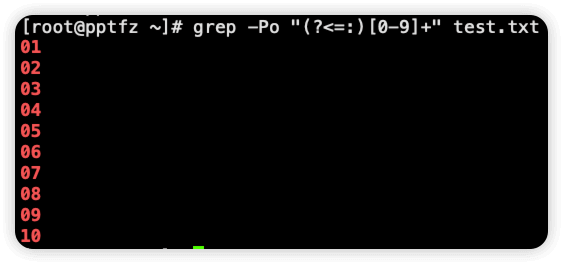
(?<=:) 为固定格式,等号右边的冒号表示要�截取冒号右边的内容,[0-9]+ 表示冒号右边为数字
$ grep -Po "(?<=:)[0-9]+" test.txt
01
02
03
04
05
06
07
08
09
10
示例2:截取IP地址
查看ip地址
$ ip a s eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 52:54:00:3b:63:f9 brd ff:ff:ff:ff:ff:ff
inet 10.0.16.17/22 brd 10.0.19.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe3b:63f9/64 scope link
valid_lft forever preferred_lft forever
() 中有小于号,表明要截取字符串右边的内容
$ ip a s eth0 | grep -Po '(?<=inet )[0-9.]+'
10.0.16.17
() 中没有小于号,表明要截取字符串左边的内容
$ ip a s eth0 | grep -Po '[0-9.]+(?=/22)'
10.0.16.17